[에이블런][AI 스타트업 유니터비시티] 0806 TIL
딥러닝 기초
딥러닝 (Deep Learning)
인간의 뉴런을 모방한 인공신경망 기반으로 인간과 유사하게 학습하는 방법
|
구분
|
전통적인 머신러닝
|
딥러닝
|
|
데이터 규모
|
• 소규모 ~ 중규모 데이터셋에 적합
|
• 대규모 데이터셋에서 뛰어난 성능
|
|
데이터 유형
|
• 주로 정형 데이터
|
• 정형 및 비정형 데이터(이미지, 음성, 텍스트 등)
|
|
특징 추출
|
• 수동적특징추출필요
|
• 자동특징학습
|
|
알고리즘 복잡도
|
• 비교적 단순한 알고리즘 사용
|
• 복잡한 다층 신경망 사용
|
|
해석 가능성
|
• 대체로 해석이 용이함
|
• 해석이 상대적으로 어려움 (블랙박스)
|
|
계산 자원
|
• 상대적으로 적은 컴퓨팅 파워 필요
|
• 높은 컴퓨팅 파워와 GPU 필요
|
|
학습 시간
|
• 비교적빠름
|
• 일반적으로 오래 걸림
|
|
데이터 유형
|
• 주로 정형 데이터
|
• 정형 및 비정형 데이터(이미지, 음성, 텍스트 등)
|
|
주요 활용 예시
|
• 금융 : 사기탐지, 신용평가
• 의료:질병예측및진단 • 제조 : 품질관리, 재고관리 • 마케팅:고객세분화 |
|
인공신경망(ANN, Artificial Neural Network)
생물학적 신경망(뉴런의 연결 구조)에서 영감을 받아 설계된 기계학습 모델
https://namu.wiki/w/%EC%9D%B8%EA%B3%B5%EC%8B%A0%EA%B2%BD%EB%A7%9D
인공신경망
人 工 神 經 網 / artificial neural network 인공신경망은 행렬 수학을 모델로 삼아 소프
namu.wiki
퍼셉트론
생물학적 뉴런의 기본적인 작동 원리를 단순화하여 모방한 인공 신경망의 기본 단위

여러 신경세포로부터 전달되어 온 신호들이 합산되고 합산된 값은 활성화 함수를 거친 후 출력 신호를 보낸다.
|
𝑥
|
입력
|
여러 개의 특징(feature) 입력
|
|
𝑤
|
가중치
|
입력의 중요도.
학습 과정에서 오차를 최소하하도록 조정. |
|
𝑏
|
편향
|
추가적인 상수 입력
|
|
∑
|
신호 합산
|
각 입력에 가중치를 곱한 후 모든 결과를 더하고 편향값을 추가
|
|
𝑓
|
활성화 함수
|
다음뉴런이활성화될것인지결정 (Relu, Sigmoid, Than 등 여러 종류의 활성화 함수가 있음)
|
|
𝑦
|
출력
|
단일 출력
|
인공신경망(ANN, Artificial Neural Network)

입력층(Input Layer)
✓ 모델이 학습할 데이터를 받는다.
✓ 각 노드는 하나의 입력 특성(feature)을
은닉층(Hidden Layer)
✓ 입력 출력 사이의 복잡한 패턴을 학습하며 weight와 bias를 조정한다.
나타낸다.
출력층(Output Layer)
✓ 모델의 최종 예측 결과를 출력한다.
✓ 출력 노드의 수는 해결하려는 문제의 성격 에 따라 달라진다.
심층신경망(DNN, Deep Neaural Network)
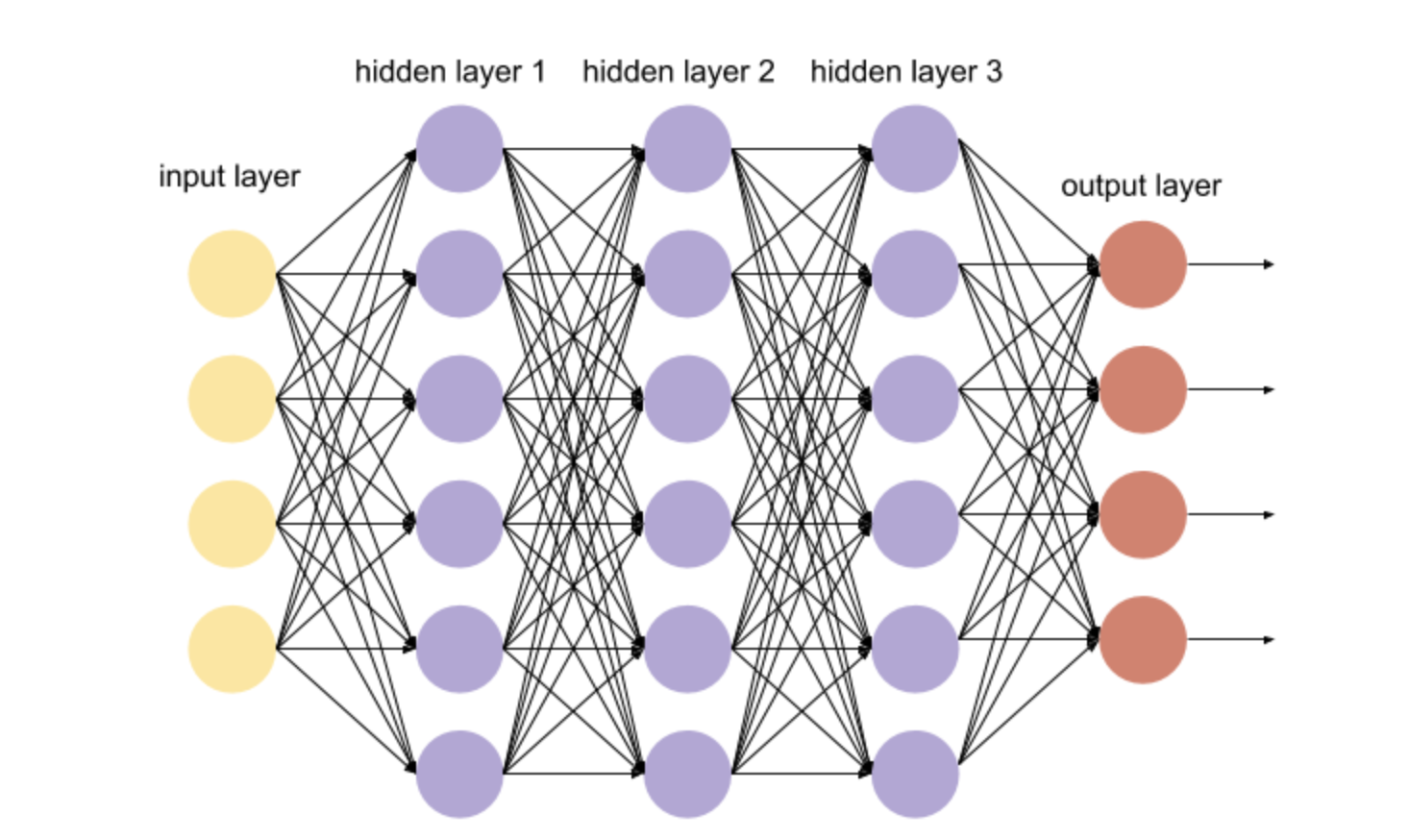
레이어가 한 층으로만 구성된 것이 아니라 깊은 층으로 구성된 인공 신경망
인공신경망의 구성요소
|
노드
Node |
|
|
층
Layer |
• 입력층(Input Layer), 은닉층(Hidden Layer), 출력층(Output Layer)으로 구성
|
|
가중치
Weight |
• 뉴런간연결강도를나타내는값.학습과정에서조정되는주요매개변수.
|
|
편향
Bias |
• 각 뉴런의 활성화 임계값을 조절하는 상수항
|
|
활성화 함수
Activation Function |
|
활성화 함수
입력신호의 총합을 그대로 사용하지 않고, 입력신호의 총합이 활성화를 일으키는지 아닌지를 정하는 역할로, 입력 신호를 규칙에 따라 출력 신호로 변환하는 함수

▪️시그모이드(Sigmoid) 함수
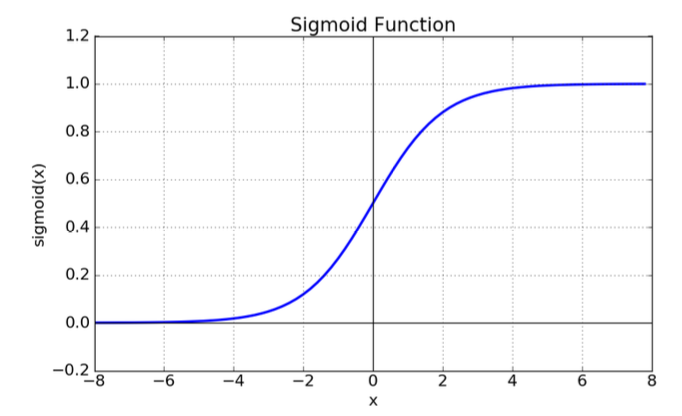
여러 뉴런에서 들어오는 신호 세기를 모아서
그 값이 0보다 클수록 1에 가깝고,
0보다 작을수록 –1에 가까운 숫자로 바꾸어주는 함수
기울기 소멸 문제
은닉층을 여러 단계 거치는 딥러닝에서 가중치를 수정하 기 위해 미분을 반복적으로 사용하면서 기울기가 0이 되 어버려 학습이 중단되는 문제가 있음
=> 이진분류의 출력층에서 사용
활성화 함수
▪️하이퍼볼릭텐젠트(Tanh) 함수
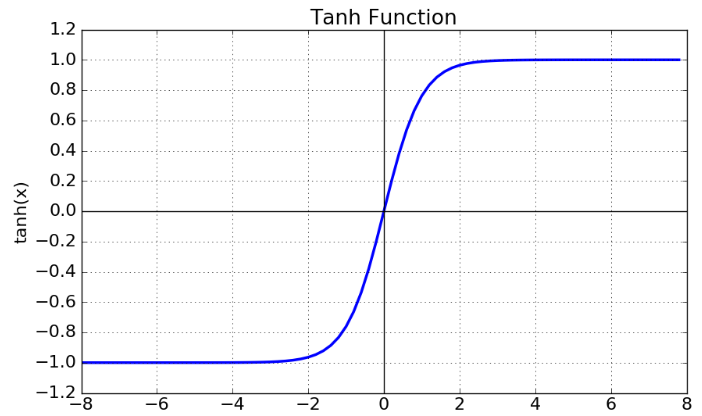
출력값이 0에 가까워지면 신경망이 잘 학 습하지 못하는 시그모이드 함수의 한계점 을 개선한 함수.
작은 신호를 -1에 가까운 숫자로 바꾸어 내보낸다.
▪️렐루(ReLU) 함수(다중분류 : lelu함수 사용)
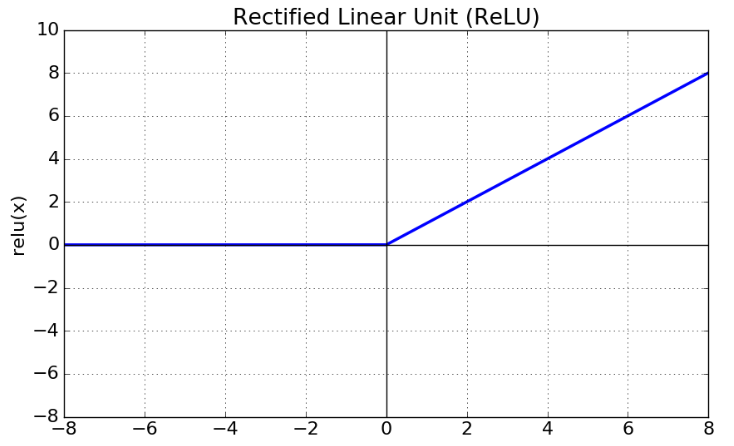
시그모이드함수와 하이퍼볼릭탄젠트함수의 경우 입력값이 아무리 커도 1보다 큰 수로 내 보내지 않는 문제가 있음.
렐루(ReLu) 함수는 입력값이 0보다 크면 입 력받는 값을 그대로 출력하여 성능을 높임
=> 히든층에서 사용
▪️ 리키렐루(Leaky ReLU) 함수
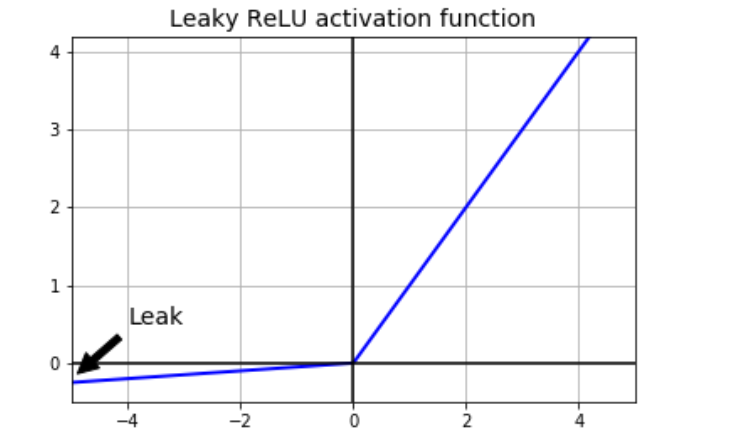
https://wooono.tistory.com/209
입력값이 음수일 경우 출력값이 0으로 같다는 렐루함수의 단점을 보완
입력값이 0보다 작을 때에 미세하게나마 차이 가 나는 음수를 출력
▪️ 소프트맥스(Softmax) 함수

분류 문제에서 최종 결과값을 총 합이 1이 되도록 정규화하는 데 사용하는 함수
=> 다중분류의 출력층에서 사용
--------------------------------------------------------------------------------------------
인공신경망의 학습
▪️에폭 수(epochs), 배치 크기(batch size)
epochs
✓ epoch : 전체 데이터 셋에 대한 한번의 학습 과정이 완료되는 단위
✓ epochs : 전체 데이터셋을 몇 번 반복해서 학습할지 결정
batch_size
✓ 한 번의 학습단위(한번의 역전파를 통해 가중치 업데이트하는 단위)에서 사용되는 훈련데이터의 크기
✓ 전체 데이터셋을 여러 작은 배치로 나누어 학습하기 위함
✓ 메모리 사용량과 학습 속도에 직접적인 영향을 미친다.

[딥러닝] 헷갈리는 개념 - epoch? batch size? iteration?
cnn 학습을 진행하다보니 이용하게 된 epoch, batch size 개념을 정확하게 짚고 기록에 남기고 싶어 포스팅 하게 되었다.다루어야 할 데이터가 너무 많기도 하고(메모리 부족), 한번의 계산으로 최적
velog.io
▪️학습률(Learning Rate) : 가중치가 없데이트되는 크기
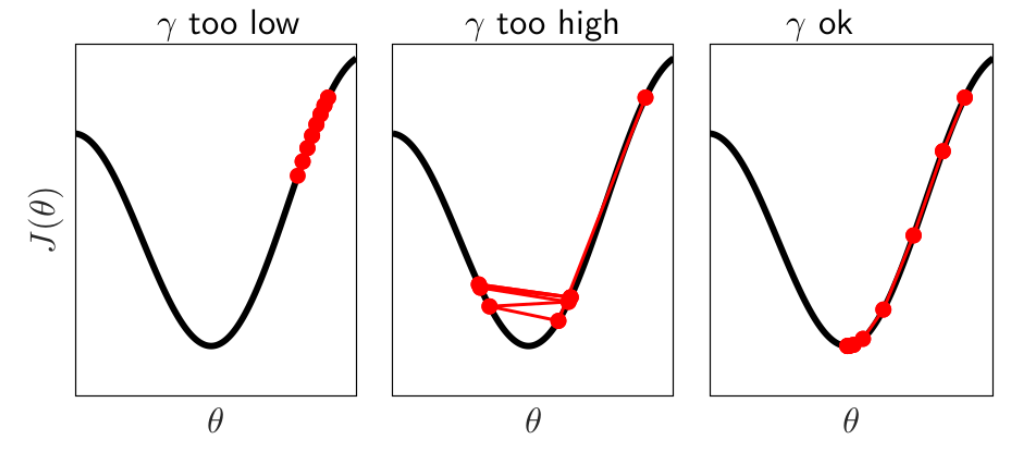
[출처] https://deeplearningmath.org/tricks-of-the-trade.html
▪️인공신경망의 학습 프로세스
학습 파라미터 지정
- 네트워크 구조 (층의 수, 노드의 수)
- 학습률, 배치크기, 에폭 수
- 활성화함수
- 손실함수
- 최적화 알고리즘(adam)
신경망 실행
- 순전파(Forward Propagation)
- 입력 데이터를 네트워크 에 통과
- 각 층에서 가중치와 편향 을 이용해 계산 수행
- 활성화함수를통해각뉴 런의 출력 생성
손실함수 실행
- 네트워크의 출력값과 실 제 레이블 간의 오차 계산
- 모델의 예측 성능 수치화
가중치 수정
반복(설정된 에포크 수만큼 반복)신경망 실행 -> ~ -> 가중치 수정
- 역전파(Back Propagation)
- 손실값에따라각가중치 에 대한 그레디언트(기울 기) 계산
- 가중치 업데이트
※ 인공신경망의 파라미터 개수 : 모든 weigh와 bias의 개수의 총 합
실습01. 폐암 수술환자 생존 예측
인공신경망 설계와 구현(이진분류) 불균형 클래스 처리
▪️문제정의
배경
폐암은 전 세계적으로 높은 사망률을 보이는 암종 중 하나이다. 폐암 수술은 많은 환자들에게 주요 치료 방법으로 사용되지만, 수술 후 생존율은 다양한 요인에 의해 영향을 받을 수 있다. 생존 예측은 의사와 환자 모두에게 중요한 정보를 제공하며, 치료 계획 수립과 환자의 삶의 질 향상에 기여할 수 있다. 정확한 생존 예측 모델은 의사들이 개별 환자의 위험도를 평가하고, 보다 적절한 치료 방법을 결정하는 데 도움이 된다.
목적
수술하기 전에 환자의 수술후 생존 가능성을 예측하여 환자의 치료 계획 수립에 도움을 제공한다.
목표
폐암 수술을 받은 환자의 임상 데이터와 수술 관련 정보를 바탕으로, 수술 후 일정 기간(예: 1년, 5년) 내 생존 여부를 예측하 는 모델을 개발한다.
from tensorflow.keras.models import Sequential
- Sequential 모델 : 순차적으로 레이어 층을 더해주는 순차모델
from tensorflow.keras.layers import Dense
- Dense 레이어 : fully-connected layer(전결합층)
*전결합층 : 모든 노드들이 엣지로 연결되어 있는 형태
# 데이터 전처리 및 시각화를 위한 라이브러리
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('ggplot')
# 딥러닝을 위한 라이브러리
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense
#https://www.kaggle.com/datasets/sojinoh/thoraricsurgery-dataset
#폴란드의 브로츠와프 의과대학에서 2013년 공개한 폐암 수술 환자의 수술 전 진단 데이터와 수술 후 생존 결과를 기록한 실제 의료 기록 데이터
#입력(속성값 17개): 17가지의 환자 상태 (종양의 유형, 폐활량, 호흡 곤란 여부, 고통 정도, 기침, 흡연, 천식 여부 등)
#출력(판정결과 1개): 수술 후 생존 결과(1=수술 후 생존했음/ 0= 수술 후 사망했음)
# 데이터 불러오기
df = pd.read_csv('https://raw.githubusercontent.com/JayoungKim-ai/ML_dataset/main/ThoraricSurgery.csv', header=None)
df.head(3)
# 데이터 분포 시각화
import matplotlib.pyplot as plt
fig, axes = plt.subplots(4, 5, figsize=(15,10))
axes = axes.flatten()
for i in range(18):
sns.histplot(df.iloc[:,i], ax=axes[i])
plt.tight_layout()
plt.show()
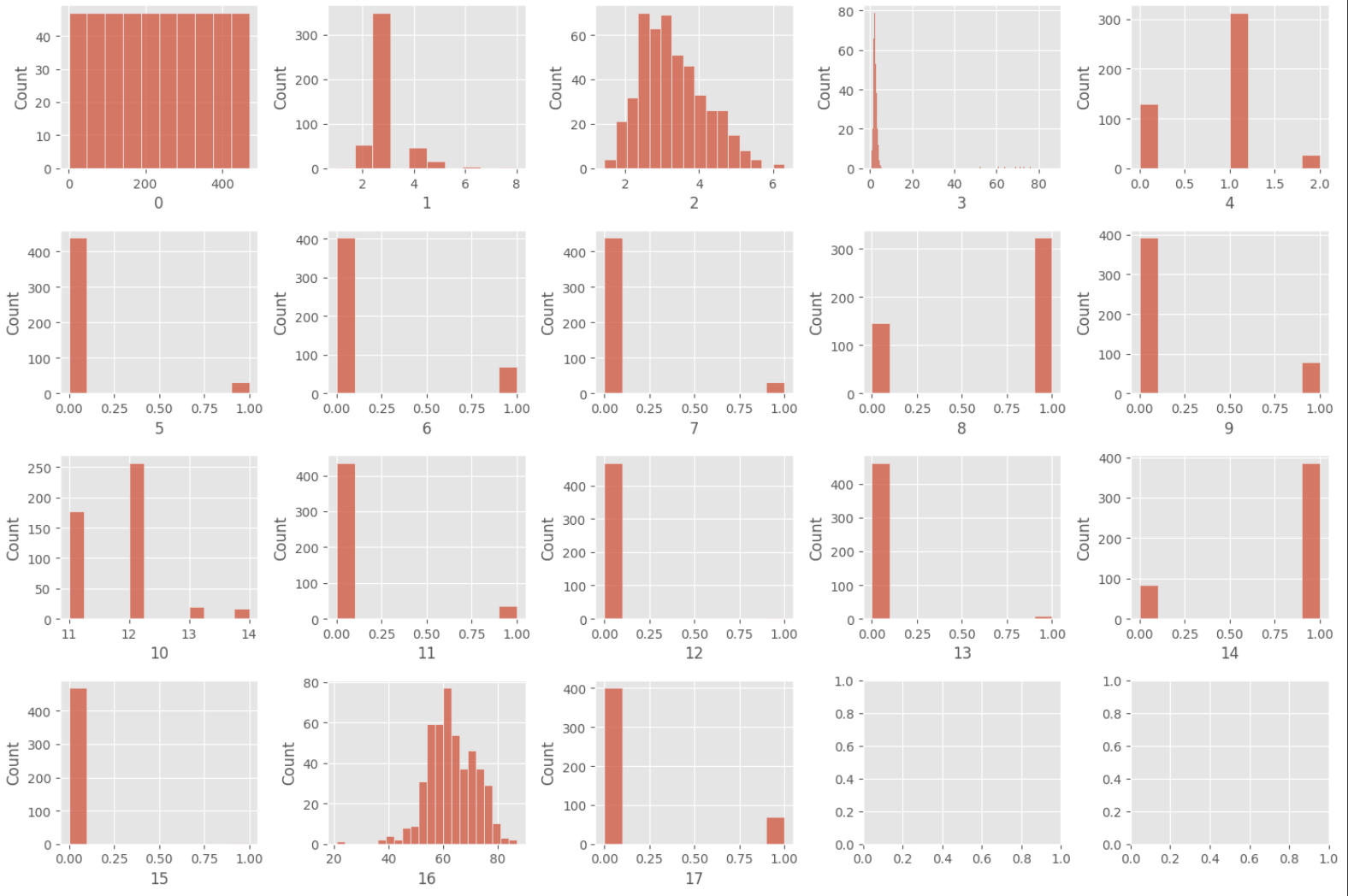

데이터 전처리(신경망의 경우 정규화 과정이 중요함)
*MinMaxScaler : 0~1사이의 값으로 정규화 하는 스케일링 방법
# feature 정규화
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# MinMaxScaler 객체 생성
scaler = MinMaxScaler()
# 0~16열 데이터 정규화
scaled_data = scaler.fit_transform(df.iloc[:, 0:17])
# 정규화된 데이터를 DataFrame으로 변환
scaled_df = pd.DataFrame(scaled_data, columns=df.columns[0:17])
# 원본 DataFrame의 17번째 열(target)을 정규화된 DataFrame에 추가
scaled_df[17] = df.iloc[:, 17]
# 결과 확인
scaled_df.head()

# 특성과 타겟 분리
X = np.array(scaled_df.iloc[:,1:-1]) # 속성 : 수술 전 상태
y = np.array(df.iloc[:,-1]) # 클래스 : 수술 후 생존 결과
print(X.shape, y.shape)# 훈련세트와 테스트세트 분리
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
#분류문제에서 클래스를 균형있게 분리하는 방법 stratify=y*분류문제에서 클래스를 균형있게 분리하는 방법 stratify=y
pd.DataFrame(y_train).value_counts()
#0 320
31 56
#Name: count, dtype: int64
pd.DataFrame(y_test).value_counts()
#0 80
#1 14
#Name: count, dtype: int64
모델 구조 설계
# 모델객체 생성
model = Sequential()
# 입력층 : 16의 특성을 가지므로 16의 노드 필요
model.add(Input(shape=(16,)))
# 히든층 : 30개의 노드. 히든층의 활성화함수는 주로 relu 사용
model.add(Dense(30, activation='relu')) # 히든층
model.add(Dense(30, activation='relu')) # 히든층
# 출력층 : 이진분류이므로 1개의 노드. 이진분류의 활성화함수는 sigmoid 함수 사용
model.add(Dense(1, activation='sigmoid'))#학습 환경 설정
#loss : 손실함수(모델의 실제값과 예측값의 오차를 측정하기 위한 함수)
#optimizer : 모델의 가중치를 업데이트하는 방법 (경사하강법의 종류)
#metrics : 모델의 성능평가기준
model.compile(loss='binary_crossentropy'
, optimizer='SGD'
, metrics=['accuracy'])
모델 학습
- epochs : 전체 데이터셋에 대한 한번의 학습이 완료되는 단위 (ex.책 한권 떼기)
- batch_size : 대량의 데이터 학습 시 메모리의 한계로 전체 데이터셋을 한번에 넣을 수 없어서 나누어 넣어준다 (ex. 책 한권을 한번에 학습하기 어려우니 나누어 학습)
history=model.fit(X_train, y_train, epochs=100, batch_size=32)
모델 평가
# 테스트 데이터로 모델 평가
model.evaluate(X_test, y_test, batch_size=10)
-> accuracy는 0.8115로 나타났지만, 추가적인 평가지표를 확인 할 필요가 있음
-> confusion matrix 진행
# confusion matrix
from sklearn.metrics import confusion_matrix, classification_report
# 예측값 생성
y_pred = model.predict(X_test)
y_pred = (y_pred > 0.5).astype(int) # 0.5를 기준으로 0과 1로 변환
# 혼동행렬 생성
cm = confusion_matrix(y_test, y_pred)
# 혼동행렬 시각화
plt.figure(figsize=(4, 3))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
plt.show()
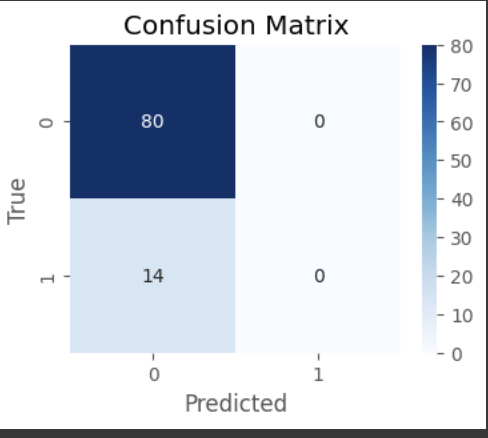
예측을 잘하지 못하는 것을 확인 가능.
▪️클래스 불균형 문제
모델편향
다수 클래스(예: 생존자)에 더 잘 맞춰지게 되어, 소수 클래스 (예: 사망자)에 대한 예측 성능이 떨어질 수 있다.
성능 지표의 왜곡
정확도만으로는 모델의 실제 성능을 제대로 평가하기 어렵다. 다수 클래스에서 높은 정확도를 보이지만, 이는 소수 클래스에 서의 예측 성능이 반영되지 않는 왜곡된 결과일 수 있다
=> solution
▪️클래스 불균형 문제 해결 방안 : Undersampling, Oversampling

# prompt: random 오버샘플링하여 다시 훈련하고, accyrach, precision, recall 출력하고, confusion matrix 시각화해줘.
import matplotlib.pyplot as plt
from imblearn.over_sampling import RandomOverSampler
# RandomOverSampler 객체 생성
ros = RandomOverSampler(random_state=42)
# 훈련 데이터 오버샘플링
X_train_resampled, y_train_resampled = ros.fit_resample(X_train, y_train)
# 모델 재학습
model.fit(X_train_resampled, y_train_resampled, epochs=100, batch_size=32)
# 테스트 데이터로 모델 평가
y_pred = model.predict(X_test)
y_pred = (y_pred > 0.5).astype(int)
# 평가 지표 출력
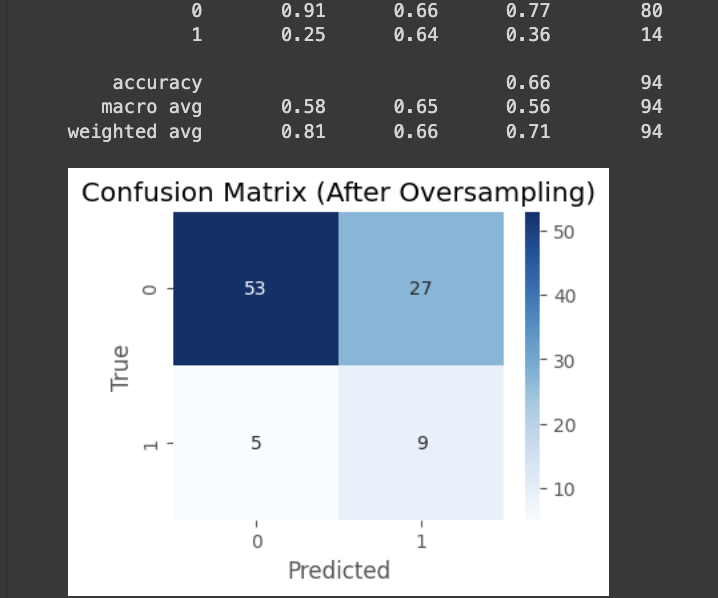
print(classification_report(y_test, y_pred))
# 혼동 행렬 시각화
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(4, 3))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix (After Oversampling)')
plt.show()
딥러닝_02.iris품종분류
▪️문제정의
- iris의 꽃잎과 꽃받침의 크기에 따라 iris 품종을 분류하는 것이 목적
- 미국의 식물학자 에드거 앤더슨(Edgar Anderson)이 수집
- 1936년 통계학자 로널드 피셔(Ronald Fisher)가 발표한 논문에서 처음 소개
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('ggplot')
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense
df = sns.load_dataset('iris')
df.sample(3)
# 상관도 그래프
sns.pairplot(df, hue='species')

# 특성, 타겟 분리
X = np.array(df.iloc[:,:-1])
y = np.array(df.iloc[:,-1])
print(X.shape, y.shape)
# 타겟변수 원핫인코딩
df_ohe = pd.get_dummies(df['species'])
df_ohe.sample(5)
# 타겟변수 넘파이 배열 형태로 변경
y = df_ohe.to_numpy()
print(y[:5])
# 클래스 이름 저장
class_names = df_ohe.columns
print(class_names)
# 훈련셋, 테스트셋 분할
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3, stratify=y)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
pd.DataFrame(y_train).value_counts()
모델 생성 및 훈련
# 모델 객체 생성
model = Sequential()
# 모델 구조 설계
model.add(Input(shape=(X.shape[1],)))
model.add(Dense(12, activation='relu', name='dense1'))
model.add(Dense(8, activation='relu', name='dense2'))
model.add(Dense(3, activation='softmax', name='dense3')) #출력층 3개, 다중분류이므로 softmax 함수 사용
model.summary()
# 모델 컴파일
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
#loss 함수는 다중분류이므로 categorical_crossentropy
# 모델 학습 (훈련세트로 학습)
history = model.fit(X_train, y_train, epochs=100, batch_size=16)
#batch_size는 16으로 100번 진행

# 모델의 학습 히스토리
df_history = pd.DataFrame(history.history)
df_history
plt.figure(figsize=(10,4))
plt.subplot(1,2,1)
plt.plot(df_history['loss'], marker='.')
plt.title('loss')
plt.subplot(1,2,2)
plt.plot(df_history['accuracy'], marker='.')
plt.title('accuracy')
*학습이 반복되면서 losssms 감소하고 accuracy는 증가하는 것을 확인할 수 있음
모델 성능 평가
# 테스트데이터로 평가
loss, accuracy = model.evaluate(X_test, y_test)
print('loss:',loss)
print('accuracy:',accuracy)
#2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 7ms/step - accuracy: 0.9095 - loss: 0.2702
#loss: 0.26694613695144653
#accuracy: 0.9111111164093018
# prompt: confusion matrix 시각화
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import confusion_matrix, classification_report
# 예측값 생성
y_pred = model.predict(X_test)
y_pred_class = np.argmax(y_pred, axis=1)
y_test_class = np.argmax(y_test, axis=1)
# 혼동행렬 생성
cm = confusion_matrix(y_test_class, y_pred_class)
# 혼동행렬 시각화
plt.figure(figsize=(4,4))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=class_names, yticklabels=class_names)
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title('Confusion Matrix')
plt.show()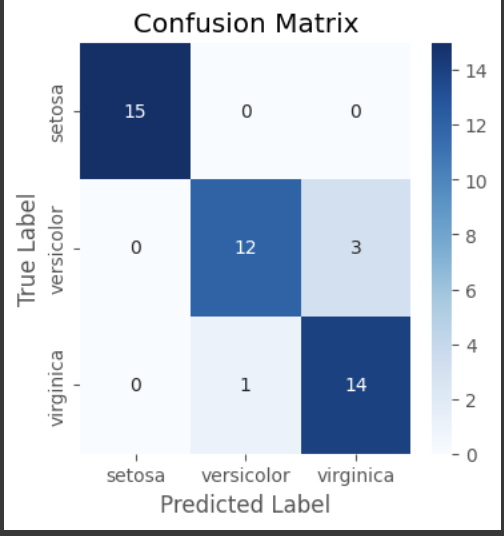
예측하기
# 예측할 만한 데이터 생성
new_data = np.array([[5.1, 3.5, 1.4, 3.2]]) # 예시 데이터
# 예측 수행
predictions = model.predict(new_data)
print(predictions)
# 예측 결과 출력
predicted_class = np.argmax(predictions, axis=1)
print(predicted_class)
print('Predicted class:', class_names[predicted_class[0]])
[[9.9103713e-01 8.8388110e-03 1.2406868e-04]]
[0]
Predicted class: setosa
# 예측할 만한 데이터 생성
new_data = np.array([[5.1, 3.5, 1.4, 1.2]]) # 예시 데이터
# 예측 수행
predictions = model.predict(new_data)
print(predictions)
# 예측 결과 출력
predicted_class = np.argmax(predictions, axis=1)
print(predicted_class)
print('Predicted class:', class_names[predicted_class[0]])
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 21ms/step
[[9.9480104e-01 5.1457193e-03 5.3229225e-05]]
[0]
Predicted class: setosa
*모델설정, 활성화함수, loss, optimizer, layer 설정이 중요함
[과적합 회피를 위한 모델 정규화 기법]_정기예금 가입여부 예측
▪️모델의 과적합(Overfitting)과 부적합(Underfitting)
- 과적합(Overfitting) 학습데이터에 성능이 좋지만 실제 데이터에 관해 성능이 떨어지는 현상
- 부적합(Underfitting) 적정 수준의 학습을 하지 못해 실제 성능이 떨어지는 현상
▪️ 과적합 회피 방법
학습과 동시에 검증을 병행하여 진행 / early stopping → 검증 오차가 줄지 않으며 학습을 중단
문제 정의 : 은행의 마케팅 캠페인 데이터를 사용하여 고객의 정기예금 가입 여부를 예측합니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('ggplot')
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense
# 컬럼 및 독립변수와 종속변수 확인
display(df.head())
display(df.tail())
# 독립변수와 종속변수 분리
X = df.drop('deposit', axis=1)
y = df['deposit']
y = y.map({'yes': 1, 'no': 0})
y.sample(5)
# 범주형 변수만 추출하기
objs = X.select_dtypes(include="object").columns.tolist()
# 수치형 변수만 추출하기
nums = df.select_dtypes(exclude="object").columns.tolist()
print(objs)
print(nums)
from sklearn.preprocessing import LabelEncoder
# LabelEncoder 객체를 저장할 딕셔너리
encoders = {}
# 원본은 그대로 두고 복사본으로 작업
X_preprocessed = X.copy()
# 각 열에 대해 레이블 인코딩 수행
for obj in objs:
le = LabelEncoder()
X_preprocessed[obj] = le.fit_transform(X[obj])
encoders[obj] = le # 각 열의 LabelEncoder 저장
# 인코딩된 결과 확인
for obj in objs:
print(f"Column: {obj}")
print(f"Classes: {encoders[obj].classes_}")
print(f"Encoded Values: {X_preprocessed[obj].unique()}")
print()
display(X.head())
display(X_preprocessed.head())
# 수치형데이터의 스케일링
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_preprocessed[nums] = scaler.fit_transform(X[nums])
display(X.head())
display(X_preprocessed.head())
# 훈련 및 테스트 데이터 분할
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_preprocessed, y, test_size=0.2, random_state=42)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
# 모델 정의
model = Sequential()
model.add(Input(shape=(X_train.shape[1],)))
model.add(Dense(30, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 모델 컴파일
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
#optimizer = adam, loss = 이진분류이므로 binary_crossentropy, metrics = accuracy
# 모델 훈련 (300 에포크)
history = model.fit(X_train, y_train, epochs=300, batch_size=32, validation_split=0.25)
#과적합을 발생시키기 위하여 300번 반복을 진행
#validation_split : 기존 - 훈련 테스트 세트로 분리 -> 차이점 - 훈련 테스트 세트를 훈련 세트와 검증 세트로 나눔
#훈련을 하면서 검증도 진행한다는 장점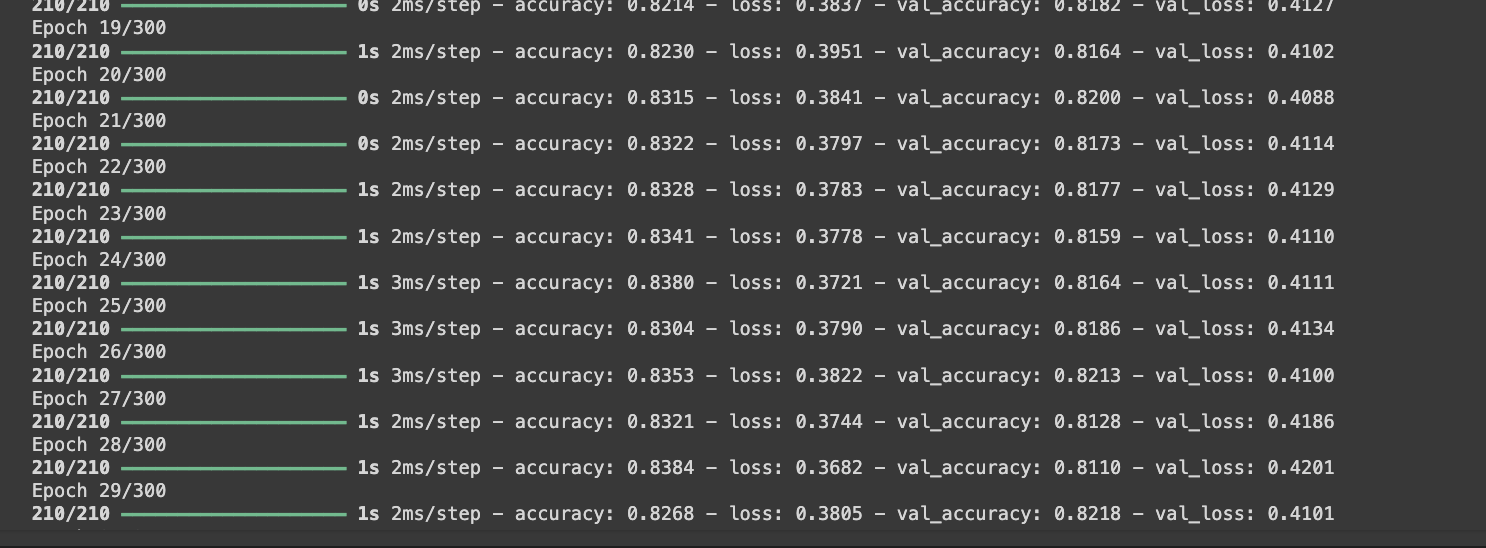
# 학습 현황
df_history = pd.DataFrame(history.history)
df_history.tail()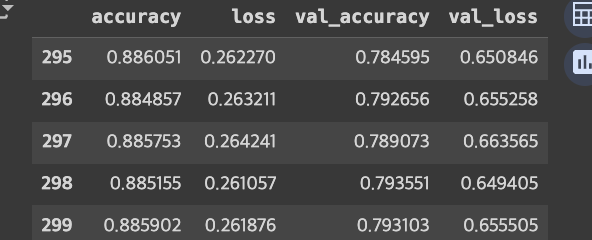
sns.lineplot(data=df_history, x=df_history.index, y='loss', color='b', label='loss')
sns.lineplot(data=df_history, x=df_history.index, y='val_loss', color='r', label='val_loss')
plt.legend()

*epoch를 수동으로 조정할 필요 있음
# 모델 정의
model = Sequential()
model.add(Input(shape=(X_train.shape[1],)))
model.add(Dense(30, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 모델 컴파일
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 모델 훈련 (300 에포크)
history = model.fit(X_train, y_train, epochs=15, batch_size=32, validation_split=0.25).
.
<코드 생략>


(epoch 를 15로 조정한 결과 파란 실선과 빨간 실선의 추이가 비슷한 것을 확인할 수 있음)
이런 식으로 epoch를 조정하는 방법은 비효율적이라는 단점이 존재함.
solution -> earlystopping 사용
# Early Stopping을 위한 라이브러리
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
# Early Stopping 객체 생성
early_stopping = EarlyStopping(monitor='val_loss', patience=30, restore_best_weights=True)
# 모델 저장을 위한 객체
checkpointer = ModelCheckpoint(filepath='best_model.keras', monitor='val_loss', save_best_only=True
# 모델 정의
model = Sequential()
model.add(Input(shape=(X_train.shape[1],)))
model.add(Dense(30, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 모델 컴파일
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 모델 훈련 (1000 에포크)
history = model.fit(X_train, y_train, epochs=1000, batch_size=32, validation_split=0.25
, callbacks=[early_stopping, checkpointer])monitor='val_loss' val_loss 검증 손실을 모니터링
patience=30 30번의 에포크 동안 개선이 없으면 훈련을 중단
restore_best_weights=True 훈련이 중단된 후 가장 성능이 좋았던 모델의 가중치를 복원
save_best_only=True 모니터링하는 성능 지표가 가장 좋을 때만 모델을 저장
restore_best_weights=True 훈련이 중단된 후 가장 성능이 좋았던 모델의 가중치를 복원
* callbacks=[early_stopping, checkpointer]) 지정
epoch는 1000번을 지정하였고 early_stopping 되는 지점을 확인한 결과

46번까지 진행된 것을 확인할 수 있음
# 저장된 모델 불러오기
from tensorflow.keras.models import load_model
loaded_model = load_model('best_model.keras')
# 테스트 데이터 예측
y_pred = loaded_model.predict(X_test)
y_pred = (y_pred > 0.5).astype(int) #0.5를 기준으로 0과 1로 변환
# 모델 평가
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nConfusion Matrix:\n", confusion_matrix(y_test, y_pred))
딥러닝 모델의 과적합 회피 방법
▪️Underfitting, Overfitting이 아닌 Generalization 모델을 만드는 방법
① Data Augmentation (데이터 증강) -> 이미지 데이터에서 주로 활용
② Early stopping (조기 종료)
③ Dropout -> 모델의 복잡도를 줄이는 방법
④ weight Regulaliztion (가중치 정규화) : L2, L1 ->
⑤ Batch Normalization (배치 정규화)
⑥ 데이터 정규화 및 표준화 - 데이터 값의 범위를 변환시켜 학습 결과가 특정 데이터 분포에 과적합될 가능성을 낮춘다.
▪️Data Augmentation (데이터 증강)
학습 데이터를 증강하여 모델이 다양한 데이터 패턴을 학습하게 하여 일반화 성능을 높인다.
✓ 데이터 증강은 주로 이미지, 오디오, 텍스트와 같은 비정형데이터에서 많이 사용된다.
✓ 예시: 이미지 회전, 이동, 확대/축소, 노이즈 추가 등.
▪️Early Stopping (조기 종료)
검증 손실이 개선되지 않을 때 학습을 조기에 종료하는 기법.
✓ 일반적으로 patience 파라미터를 사용하여 일정 에포크 동안 개선이 없을 때 학습을 종료한다.
▪️Dropout
학습 중 무작위로 일부 뉴런을 비활성화하여 모델의 과적합을 방지하는 기법.
✓ 학습 도중에 랜덤하게 노드와 그 연결을 제거하여 각 노드)끼리 서로 과도하게 의존하는 현상을 방지한다.
✓ Dropout 비율을 설정하여 비활성화할 뉴런의 비율을 조정한다.
✓ epoch마다 랜덤하게 설정되기 때문에 다양한 모델을 학습하는 앙상블 효과를 낼 수 있다
# prompt: dropout 적용해줘. 모델 이름은 model_do. 평가도 해줘.
from tensorflow.keras.layers import Dropout
# 모델 정의 (Dropout 추가)
model_do = Sequential()
model_do.add(Input(shape=(X_train.shape[1],)))
model_do.add(Dense(30, activation='relu'))
model_do.add(Dropout(0.2)) # Dropout 추가
model_do.add(Dense(12, activation='relu'))
model_do.add(Dropout(0.2)) # Dropout 추가
model_do.add(Dense(12, activation='relu'))
model_do.add(Dropout(0.3)) # Dropout 추가
model_do.add(Dense(1, activation='sigmoid'))
# 모델 컴파일
model_do.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Early Stopping 객체 생성
early_stopping = EarlyStopping(monitor='val_loss', patience=30, restore_best_weights=True)
# 모델 저장을 위한 객체
checkpointer = ModelCheckpoint(filepath='best_model_do.keras', monitor='val_loss', save_best_only=True)
# 모델 훈련 (1000 에포크)
history_do = model_do.fit(X_train, y_train, epochs=1000, batch_size=32, validation_split=0.25
, callbacks=[early_stopping, checkpointer])
# 저장된 모델 불러오기
loaded_model_do = load_model('best_model_do.keras')
# 테스트 데이터 예측
y_pred_do = loaded_model_do.predict(X_test)
y_pred_do = (y_pred_do > 0.5).astype(int) # 0.5를 기준으로 0과 1로 변환
# 모델 평가
print("Accuracy (with Dropout):", accuracy_score(y_test, y_pred_do))
print("\nConfusion Matrix (with Dropout):\n", confusion_matrix(y_test, y_pred_do))
▪️ weight regularization : 가중치 정규화
가중치의 크기를 제한하여 모델의 복잡성을 줄이고, 과적합을 방지하는 방법.
✓ 모델이 훈련데이터를 과도하게 학습하면 → 손실함수 값이 과도하게 작아지게 된다.
✓ 가중치 규제란, 모델의 손실값이 너무 작아지지 않도록 특정한 값(함수)를 추가하는 방법이다.
✓ 즉, 학습을 방해하기 위해 손실함수에 패널티를 더하는 방식으로 훼방을 놓는다.
→ 신기하게도 불필요한 가중치는 감소하고 필요한 가중치는 더 부각되어 전체적인 모델의 성능이 개선된다.
✓ 가중치 규제에는 L1규제(L1 Regularization, Lasso), L2규제(L2 Regularization, Ridge)가 있다.
✓ L1규제 : 규제가 적용된 레이어의 모든 가중치들의 절대값들의 합을 손실함수에 더한다.
→ 불필요한 가중치를 0으로 만들어 제거되는 과정이 발생할 수 있다.
✓ L2규제 : 규제가 적용된 레이어의 모든 가중치들의 제곱의 합을 손실함수에 더한다.
→ 가중치가 작을 경우 작은 패널티, 클 경우 큰 패널티를 준다.
→ 가중치가 클수록 더 큰 패널티를 받으므로 가중치가 너무 커지는 것을 제한하여 과적합을 방지한다. (일반적으로 더 많이 사용됨.)
https://ttrhtt12.tistory.com/66
linear regression(ridge & lasso) coding implementation
to_numpy를 활용하면 행렬 연산이 가능한 형태로 변화 x의 feature는 5개 matmul은 행렬곱 함수(전치x 곱하기 x) 위의 w변수의 각각의 계수와 데이터프레임의 각 첫번째 행을 곱하기.(w곱하기 x_train) predic
ttrhtt12.tistory.com

은닉츠의 각 층에 가중치 정규화를 적용한다.
→ 가중치 정규화가 적용된 레이어의 모든 가중치들의 절대값 또는 제곱의 합을 손실함수에 더한다
L1 Reguralization
# prompt: L1 Reguralization적용해줘. 모델 이름은 model_l1. 평가도 해줘.
from tensorflow.keras.regularizers import l1
# 모델 정의 (L1 Regularization 추가)
model_l1 = Sequential()
model_l1.add(Input(shape=(X_train.shape[1],)))
model_l1.add(Dense(30, activation='relu', kernel_regularizer=l1(0.01))) # L1 Regularization 추가
model_l1.add(Dense(12, activation='relu', kernel_regularizer=l1(0.01))) # L1 Regularization 추가
model_l1.add(Dense(12, activation='relu', kernel_regularizer=l1(0.01))) # L1 Regularization 추가
model_l1.add(Dense(1, activation='sigmoid'))
# 모델 컴파일
model_l1.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Early Stopping 객체 생성
early_stopping = EarlyStopping(monitor='val_loss', patience=30, restore_best_weights=True)
# 모델 저장을 위한 객체
checkpointer = ModelCheckpoint(filepath='best_model_l1.keras', monitor='val_loss', save_best_only=True)
# 모델 훈련 (1000 에포크)
history_l1 = model_l1.fit(X_train, y_train, epochs=1000, batch_size=32, validation_split=0.25
, callbacks=[early_stopping, checkpointer])
# 저장된 모델 불러오기
loaded_model_l1 = load_model('best_model_l1.keras')
# 테스트 데이터 예측
y_pred_l1 = loaded_model_l1.predict(X_test)
y_pred_l1 = (y_pred_l1 > 0.5).astype(int) # 0.5를 기준으로 0과 1로 변환
# 모델 평가
print("Accuracy (with L1):", accuracy_score(y_test, y_pred_l1))
print("\nConfusion Matrix (with L1):\n", confusion_matrix(y_test, y_pred_l1))
print("\nClassification Report (with L1):\n", classification_report(y_test, y_pred_l1))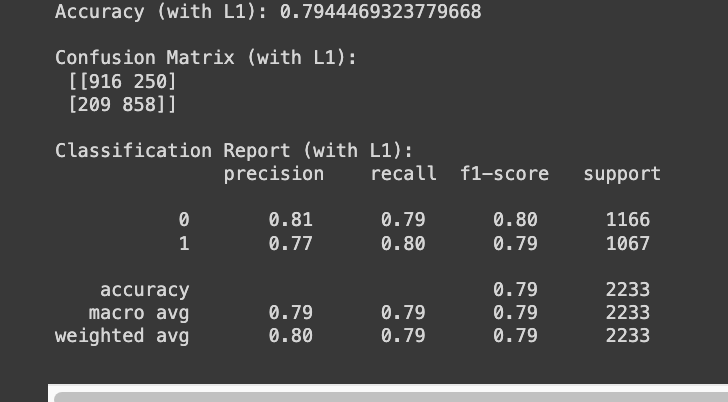
L2 Reguralization
# prompt: L2 Reguralization적용해줘. 모델 이름은 model_l2. 평가도 해줘.
from tensorflow.keras.regularizers import l2
# 모델 정의 (L2 Regularization 추가)
model_l2 = Sequential()
model_l2.add(Input(shape=(X_train.shape[1],)))
model_l2.add(Dense(30, activation='relu', kernel_regularizer=l2(0.01))) # L2 Regularization 추가
model_l2.add(Dense(12, activation='relu', kernel_regularizer=l2(0.01))) # L2 Regularization 추가
model_l2.add(Dense(12, activation='relu', kernel_regularizer=l2(0.01))) # L2 Regularization 추가
model_l2.add(Dense(1, activation='sigmoid'))
# 모델 컴파일
model_l2.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Early Stopping 객체 생성
early_stopping = EarlyStopping(monitor='val_loss', patience=30, restore_best_weights=True)
# 모델 저장을 위한 객체
checkpointer = ModelCheckpoint(filepath='best_model_l2.keras', monitor='val_loss', save_best_only=True)
# 모델 훈련 (1000 에포크)
history_l2 = model_l2.fit(X_train, y_train, epochs=1000, batch_size=32, validation_split=0.25
, callbacks=[early_stopping, checkpointer])
# 저장된 모델 불러오기
loaded_model_l2 = load_model('best_model_l2.keras')
# 테스트 데이터 예측
y_pred_l2 = loaded_model_l2.predict(X_test)
y_pred_l2 = (y_pred_l2 > 0.5).astype(int) # 0.5를 기준으로 0과 1로 변환
# 모델 평가
print("Accuracy (with L2):", accuracy_score(y_test, y_pred_l2))
print("\nConfusion Matrix (with L2):\n", confusion_matrix(y_test, y_pred_l2))
print("\nClassification Report (with L2):\n", classification_report(y_test, y_pred_l2))L1 Reguralization
▪️ Batch Normalization : 배치 정규화
• 신경망의 은닉층에 입력할 때 미니배치 단위로 데이터를 정규화하여 입력한다.
# prompt: Batch Normalization적용해줘. 모델 이름은 model_bn. 평가도 해줘.
from tensorflow.keras.layers import BatchNormalization
# 모델 정의 (Batch Normalization 추가)
model_bn = Sequential()
model_bn.add(Input(shape=(X_train.shape[1],)))
model_bn.add(Dense(30, activation='relu'))
model_bn.add(BatchNormalization()) # Batch Normalization 추가
model_bn.add(Dense(12, activation='relu'))
model_bn.add(BatchNormalization()) # Batch Normalization 추가
model_bn.add(Dense(12, activation='relu'))
model_bn.add(BatchNormalization()) # Batch Normalization 추가
model_bn.add(Dense(1, activation='sigmoid'))
# 모델 컴파일
model_bn.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Early Stopping 객체 생성
early_stopping = EarlyStopping(monitor='val_loss', patience=30, restore_best_weights=True)
# 모델 저장을 위한 객체
checkpointer = ModelCheckpoint(filepath='best_model_bn.keras', monitor='val_loss', save_best_only=True)
# 모델 훈련 (1000 에포크)
history_bn = model_bn.fit(X_train, y_train, epochs=1000, batch_size=32, validation_split=0.25
, callbacks=[early_stopping, checkpointer])
# 저장된 모델 불러오기
loaded_model_bn = load_model('best_model_bn.keras')
# 테스트 데이터 예측
y_pred_bn = loaded_model_bn.predict(X_test)
y_pred_bn = (y_pred_bn > 0.5).astype(int) # 0.5를 기준으로 0과 1로 변환
# 모델 평가
print("Accuracy (with Batch Normalization):", accuracy_score(y_test, y_pred_bn))
print("\nConfusion Matrix (with Batch Normalization):\n", confusion_matrix(y_test, y_pred_bn))
print("\nClassification Report (with Batch Normalization):\n", classification_report(y_test, y_pred_bn))

배치정규화, 드롭아웃, l2정규화 조합
# prompt: 배치정규화, 드롭아웃, l2정규화 조합
# 모델 정의 (Batch Normalization, Dropout, L2 Regularization 조합)
model_combo = Sequential()
model_combo.add(Input(shape=(X_train.shape[1],)))
model_combo.add(Dense(30, activation='relu', kernel_regularizer=l2(0.01)))
model_combo.add(BatchNormalization())
model_combo.add(Dropout(0.2))
model_combo.add(Dense(12, activation='relu', kernel_regularizer=l2(0.01)))
model_combo.add(BatchNormalization())
model_combo.add(Dropout(0.2))
model_combo.add(Dense(12, activation='relu', kernel_regularizer=l2(0.01)))
model_combo.add(BatchNormalization())
model_combo.add(Dropout(0.2))
model_combo.add(Dense(1, activation='sigmoid'))
# 모델 컴파일
model_combo.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Early Stopping 객체 생성
early_stopping = EarlyStopping(monitor='val_loss', patience=30, restore_best_weights=True)
# 모델 저장을 위한 객체
checkpointer = ModelCheckpoint(filepath='best_model_combo.keras', monitor='val_loss', save_best_only=True)
# 모델 훈련 (1000 에포크)
history_combo = model_combo.fit(X_train, y_train, epochs=1000, batch_size=32, validation_split=0.25
, callbacks=[early_stopping, checkpointer])
# 저장된 모델 불러오기
loaded_model_combo = load_model('best_model_combo.keras')
# 테스트 데이터 예측
y_pred_combo = loaded_model_combo.predict(X_test)
y_pred_combo = (y_pred_combo > 0.5).astype(int) # 0.5를 기준으로 0과 1로 변환
# 모델 평가
print("Accuracy (with Combo):", accuracy_score(y_test, y_pred_combo))
print("\nConfusion Matrix (with Combo):\n", confusion_matrix(y_test, y_pred_combo))
print("\nClassification Report (with Combo):\n", classification_report(y_test, y_pred_combo))
▪️ 데이터 정규화
• 데이터 값을 일정 범위로 변환하여 학습 결과가 특정 데이터 분포에 과적합될 가능성을 낮춘다.
✓ Standardization: 데이터 값을 평균이 0, 표준편차가 1이 되도록 변환한다.
✓ MinMax Normalization: 데이터 값을 0과 1 사이로 변환한다.
✓ Robust Normalization : 중앙값(median)과 사분위수(interquartile range, IQR)를 사용하여 데이터의 스 케일을 조정한다.(이상치가 많은 데이터에 유용)
✓ Log Normalizaion : 데이터의 범위를 조정하여 분포를 더 정규분포에 가깝게 만드는 방법. 주로 데이터가 한쪽 으로 치우쳐서 분포될 때 사용
▪️ 데이터 추가
딥러닝의 다양한 알고리즘
• 딥러닝은 인공지능(AI) 및 기계 학습(ML) 분야에서 중요한 역할을 하며, 다양한 알고리즘과 모델을 포함한다.
• 각 알고리즘들은 특정한 문제를 해결하기 위해 설계되었으며, 각각의 특성과 응용 분야가 다르다.
• 각 알고리즘은 문제의 특성에 따라 적절하게 선택되고 조합되어 사용된다.
MLP Multilayer Perceptron 다층 퍼셉트론
• 가장 기본적인 형태의 신경망으로, 여러 개의 은닉층과 활성화 함수를 사용하는 완전 연결 신 경망
• 응용 분야: 기본적인 분류 및 회귀 문제, 간단한 이미지 분류, 텍스트 분류 등.
CNN Convolutional Neural Network 합성곱 신경망
• 이미지 처리에 특화된 신경망으로, 합성곱 연산을 통해 특징을 추출하고, 풀링 레이어를 통해 차원을 축소한다.
• 응용 분야: 이미지 분류, 객체 탐지, 인스턴스 분할, 얼굴 인식, 자율 주행 등.
RNN Recurrent Neural Network 순환 신경망
• 시퀀스 데이터를 처리하기 위해 고안된 신경망으로, 이전 단계의 출력을 다음 단계의 입력으 로 사용하여 시퀀스의 순서를 반영
• 응용 분야: 시계열 예측, 자연어 처리, 음성 인식, 기계 번역 등.
LSTM Long Short-Term Memory 장단기 메모리
• RNN의 일종으로, 장기 의존성을 학습할 수 있도록 설계된 셀 구조를 가지고 있다. LSTM은 기울기 소실 문제를 해결합니다.
• 응용 분야: 긴 시퀀스 데이터 처리, 자연어 처리, 음성 인식, 기계 번역 등.
GRU Gated Recurrent Unit 게이트 순환 유닛
• LSTM의 변형으로, 비슷한 성능을 유지하면서도 더 간단한 구조를 가지고 있다.
• 응용 분야: 긴 시퀀스 데이터 처리, 자연어 처리, 음성 인식, 기계 번역 등.
Autoencoder 자동 인코더
• 입력 데이터를 압축하여 저차원 표현을 학습한 후, 이를 다시 복원하는 신경망. 특징 추출 과 차원 축소에 사용됩니다.
• 응용 분야: 차원 축소, 이상 탐지, 이미지 복원, 생성 모델 등.
GAN Generative Adversarial Network 생성적 적대 신경망
• 두 개의 신경망(생성자와 판별자)이 경쟁하며 학습하는 구조로, 생성자는 가짜 데이터를 만들고 판별자는 진짜와 가짜를 구분한다.
• 응용 분야: 이미지 생성, 비디오 생성, 스타일 변환, 데이터 증강 등
VAE Variational Autoencoder 변이형 자동 인코더
• 확률적 접근을 통해 데이터의 저차원 표현을 학습하고, 이를 기반으로 새로운 데이터를 생 성한다.
• 응용 분야: 이미지 생성, 데이터 증강, 특이점 탐지 등
Transformer 트랜스포머
• 순차적인 데이터 처리에 특화된 모델로, 셀프 어텐션 메커니즘을 사용하여 병렬로 처리할 수 있다. 자연어 처리에서 많이 사용됩니다.
• 응용 분야: 기계 번역, 텍스트 요약, 질의응답 시스템, 자연어 이해 등.
BERT Bidirectional Encoder Representations from Transformers
• 트랜스포머 기반 모델로, 양방향 문맥을 학습하여 텍스트의 의미를 더 잘 이해한다.
• 응용 분야: 자연어 처리, 텍스트 분류, 질의응답 시스템 등.
GPT Generative Pre-trained Transformer
• 트랜스포머 기반의 언어 모델로, 대량의 텍스트 데이터를 사전 학습하여 다양한 텍스트 생성 작업을 수행한다.
• 응용 분야: 텍스트 생성, 대화 시스템, 기계 번역 등.
Reinforcement Learning 강화 학습
• 에이전트가 환경과 상호작용하며 보상을 최대화하는 행동을 학습하는 방법
• 응용 분야: 게임 인공지능, 로봇 제어, 자율 주행, 최적화 문제 등.
CNN(Convolusional Neural Network)
▪️CNN 주요 알고리즘

컴퓨터 비전 활용 사례
자율주행자동차 : 차선 인식, 신호등 및 표지판 인식, 보행자 및 차량 탐지 등
얼굴인식 시스템 : 보안시스템, 스마트폰 잠금 해제, 소셜미디어 태깅 등
의료 영상 분석 : MRI, CT, 엑스레이 등 의료 영상 분석을 통한 질병 진단
소매업 분석 : 매장 내 고객 행동 분석, 상품 진열 상태 모니터링, 재고 관리 최적화 등
산업용 로봇 : 제조 공정의 품질 관리. 제품의 결함 탐지 등
농업 : 드론과 카메라를 이용하여 작물 상태 모니터링. 병충해 조기 발견. 농작물 성장 분석 등
스포츠 분석 : 경기 중 선수의 움직임 추적. 플레이 전략 분석. 선수의 퍼포먼스 개선과 부상 예방
CCTV : 이상 행동 감지
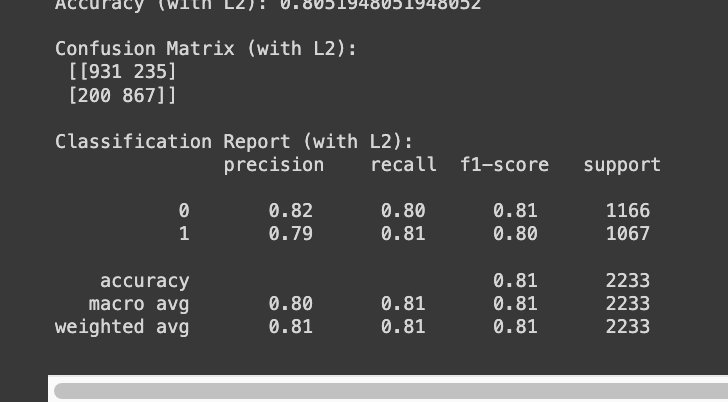
이미지의 특성 추출 (CNN) - 합성곱층, 서브샘플링층 (풀링계층) -> 예측을 위한 FC (MLP)
▪️CNN의 구성요소
Input Layer •
2차원 또는 3차원(RGB채널 포함) 배열로 구성된 이미지 입력
Convolutional Layer
• 기능 : 입력 데이터에 필터(커널)을 적용하여 합성곱 연산을 통해 특징 추출
• 핵심요소 : 필터(커널), 스트라이드(stride), 패딩(padding)
• 활성화함수 : 주로 Relu 사용
Pooling Layer
• sub sampling을 통한 차원의 축소 : max-pooling, average-pooling 활용
Flattening Layer
• Pooling Layer에서 출력된 2차원 데이터를 1차원 벡터로 변환
Fully connected layer
• Flattening 된 데이터에서 분류 수행(softmax)
Ouput Layer
• CNN이 예측한 결과 수행
Dropout
• 학습 과정에서 과적합을 방지하기 위해 임의로 뉴런을 비활성화하는 정규화 기법
Convolution Layer
▪️커널로 이미지를 스캔하며 합성곱 연산을 통하여 특성 추출
▪️ 커널에는 합성곱을 위한 가중치(weight)가 있다.
▪️ 2차원 합성곱 연산
옵션
• stride(이동하는 칸 수) = (1,1)
• padding(패딩 크기) = (0,0)

▪️ 3차원 합성곱 연산

▪️ 합성곱 신경망의 특징 추출 : 쭉 스캔하면서 필터와 같은 패턴을 찾는다.

https://huangdi.tistory.com/36
▪️ 다양한 필터를 적용하여 다양한 특징 추출.
▪️ 합성곱신경망의 가중치.
※ 합성곱신경망 하나의 가중치(weight)개수는 커널의 원소의 개수와 같다.
※ MPL에서 입력으로부터 하나의 노드와 연결되는 가중치는 입력데이터의 수와 같다.
▪️ 합성곱신경망의 편향 : 필터를 적용한 후의 결과에 더해진다.
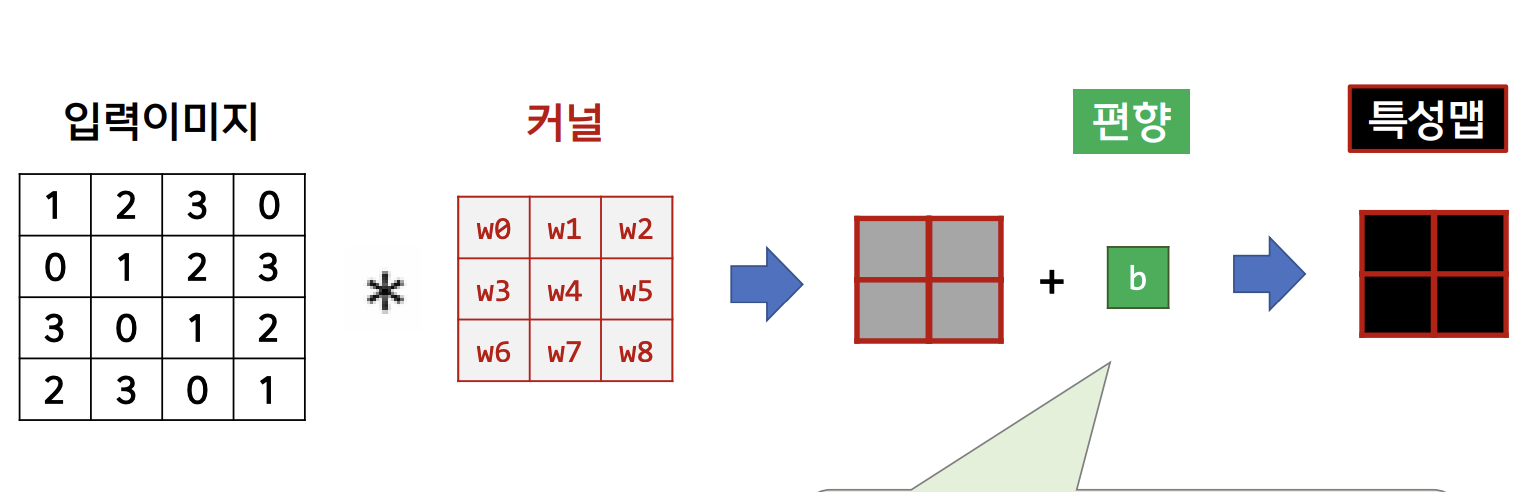
[ 편향 ]
• 편향은 한 층에 하나(1x1)만 존재한다.
• 하나의 편향을 필터를 적용한 모든 원소에 더한다.
Pooling Layer
▪️ 서브샘플링 : 합성곱 계층에서 추출된 특성맵(Feature map)의 차원을 줄이는 계층.

https://blog.naver.com/kkang9901/221776454163
풀링 계층 ,pooling
풀링은 세로 * 가로 방향의 공간을 줄이는 연산이다. 예를 들어 아래와 같이 2 * 2 영역을 원소 하나로 집...
blog.naver.com

▪️ 풀링 계층의 기능
차원축소
• 계산량을 줄여 모델의 학습 속도를 향상시킨다.
• 과적합을 방지한다.
이동불변성
• 이미지의 작은 변화에 대해 모델이 덜 민감하게 만들어준다.
특징강화
• 이미지의 주요 특징을 강화하고 덜 중요한 정보를 제거하여 특징을 더욱 명확하게 만들어준다.
dropout
▪️ 신경망의 일부 뉴런을 학습에서 제외시키는 방법
모델 복잡성 방지
• 학습과정에서 모델이 특정 뉴런에 과도하게 의존하는 것을 방지하여 모델의 일반화 능력 향상
• 학습시간 단축
• 과적합 방지
앙상블 효과
• 드롭아웃은 매번 다른 뉴런 집합을 제거하여 학습 과정에서 다양한 신경망 구조를 통해 학습하는 효과를 낸다.
• 이는 각기 다른 모델들을 앙상블한 것과 유사한 효과를 가져와 모델 의 성능을 향상시킨다.
합성곱 신경망 구성
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, Dropout
np.set_printoptions(precision=4, suppress=True)
from tensorflow.keras.datasets import mnist
# 훈련데이터, 테스트데이터 불러오기
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 데이터의 크기 확인
print('x_train.shape :', x_train.shape)
print('y_train.shape :', y_train.shape)
print('x_test.shape :', x_test.shape)
print('y_test.shape :', y_test.shape)
# 첫번째 훈련데이터 확인
img = x_train[0]
label = y_train[0]
print(img.shape)
print(label)
for i in range(28):
for j in range(28):
print(f'{img[i,j]:4d}', end='')
print()

# 10개의 훈련데이터 확인
plt.figure(figsize=(10,5))
for i in range(10):
plt.subplot(2,5,i+1)
plt.imshow(x_train[i], 'gray')
plt.title(y_train[i])
#인력 데이터 차원 변환
#28x28 형태의 데이터를 인공지능 모델에 넣기 위해 형태를 한줄로 바꾸기
#np.reshape(총 샘플 수, 1차원 속성의 갯수)
#마지막 파라미터에 -1을 사용하면 필요한 숫자를 알아서 계산하여 넣어준다.
X_train = x_train.reshape(x_train.shape[0], 28,28,1)
X_test = x_test.reshape(x_test.shape[0], 28,28,1)
print('X_train.shape:' , X_train.shape)
print('X_test.shape:', X_test.shape)#입력데이터 수치 스케일링
#정규화 : 데이터를 0~1사이로 바꾼다.
#먼저 자료형을 실수형으로 바꾼 뒤 255로 나누어준다.
#정규화를 하면 데이터의 특성이 더 잘 드러나며, 정규화하지 않은 데이터보다 학습이 잘 이루어질 수 있다.
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
Y_train = pd.get_dummies(y_train).to_numpy()
Y_test = pd.get_dummies(y_test).to_numpy()
print('Y_train.shape:', Y_train.shape)
print('Y_test.shape:', Y_test.shape)
#모델 생성
# 모델 최적화를 위한 학습자동중단, 모델 저장 설정
# 학습 자동 중단, 최종 모델 저장을 위한 라이브러리
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
# 학습 자동 중단을 위한 객체
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=10)
# 모델 저장을 위한 객체
checkpointer = ModelCheckpoint(filepath='model/mnist.keras')
인공신경망 구성 및 학습
model = Sequential()
# CNN
model.add(Conv2D(16, kernel_size=(3,3), input_shape=(28,28,1), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(32, kernel_size=(3,3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
# FC
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X_train, Y_train, epochs=1000, batch_size=200, verbose=2,
validation_split=0.25, callbacks=[early_stopping_callback, checkpointer])

예측하기
#모델이 예측한 값 : model.predict(X_test)
#np.argmax(array, axis=1) : 열 방향으로 max값의 인덱스 리턴
#np.nonzero(array) : array에서 0이 아닌 요소의 인덱스 리턴
# 모델 예측 결과
predicted_results = saved_model.predict(X_test)
predicted_results
# 모델이 예측한 클래스
predicted_classes = np.argmax(predicted_results, axis=1)
predicted_classes
#잘 예측한 데이터 살펴보기
# 모델이 예측한 값과 정답 비교하여 정확하게 예측한 값의 인덱스 골라내기
correct = np.where(predicted_classes == y_test)[0]
plt.figure(figsize=(15,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.imshow(X_test[correct[i]].reshape(28,28), cmap='gray')
plt.title(f'Predicted:{predicted_classes[correct[i]]}, class:{y_test[correct[i]]}')
plt.tight_layout()
#잘 예측하지 못한 데이터 살펴보기
# 모델이 예측한 값과 정답 비교하여 잘못 예측한 값의 인덱스 골라내기
incorrect = np.where(predicted_classes != y_test)[0]
plt.figure(figsize=(15,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.imshow(X_test[incorrect[i]].reshape(28,28), cmap='gray')
plt.title(f'Predicted:{predicted_classes[incorrect[i]]}, class:{y_test[incorrect[i]]}')
plt.tight_layout()
내 손글씨 인식
from google.colab import files
uploaded = files.upload()
# 이미지 읽어오기
import cv2
img = cv2.imread('5.jpg', cv2.IMREAD_GRAYSCALE)
# 이미지 사이즈 조절(28*28)
img = cv2.resize(img, (28,28))
# 흑백 반전
img = cv2.bitwise_not(img)
plt.imshow(img, 'gray')
# 예측하기
# 데이터 사이즈 변경
img = img.reshape([1, 28, 28, 1])
predicted = model.predict(img)
np.argmax(predicted)
순환신경망
RNN, LSTM, GRU : 순차적 데이터에서 중요한 패턴을 학습하고 예측하는 데 사용되는 딥러닝 모델
▪️RNN의 정의
Recurrent Neural Networks. 순환신경망.
• 시퀀스 데이터(순서가 중요한 데이터)를 처리하는 데 특화된 인공 신경망의 한 유형
• 이전 입력에서 학습한 정보를 '기억'하고, 이를 바탕으로 현재의 입력을 처리하여 다음 상태로 전달한다.
• 이 특성 때문에 시계열 데이터, 자연어 처리(NLP), 음성 인식 등 다양한 응용 분야 사용될 수 있다
▪️RNN의 주요 특징
순환 구조
✓ 이전 타임스텝의 출력을 다음 타임스텝의 입력으로 사용
✓ 이를 통해 시퀀스 데이터의 시간적 의존성을 학습할 수 있다.
• 상태 유지(메모리 기능)
✓ 내부 상태를 유지하며, 이전 정보가 현재의 입력에 영향을 미칠 수 있게 한다.
✓ 이는 문맥이나 시간적 흐름을 이해하는 데 중요한 역할을 한다
▪️RNN의 활용분야
• 자연어처리(NLP) : 기계번역, 감성분석, 텍스트 생성 등에서 문장의 순차적 구조를 이해하고 처리
• 음성인식 : 음성명령 인식, 음성 텍스트 변환
• 시계열 분석 : 주가 예측, 기상예보
• 비디오 분석 • 음악 생성
• 챗봇 대화 시스템
▪️연속적인 데이터에 동작하는 RNN
자연어 처리(언어모델, 기계번역, 감정분석 등)
[텍스트 분석]
텍스트 전처리
- 토큰화
- 불용어 제거
- 어간 추출 & 표제어 추출
- 클리닝
텍스트 표현 방법
- BoW (Bag of Words)
- TF-IDF
- 단어 임베딩
머신러닝 모델
- 나이브 베이즈
- SVM
- 로지스틱 회귀
딥러닝 모델
- RNN
- CNN
- 트랜스포머
Tokenization : 토큰화
- 자연어 처리를 수행하는 첫 번째 단계
- 텍스트를 컴퓨터가 처리하기 쉬운 형태로 변환하는 과정
종류
- 단어 토큰화 (Word Tokenization)
- 텍스트를 단어 단위로 나누는 과정
- 예: "나는 한국인이야." → ["나는", "한국인이야"]
- 문장 토큰화 (Sentence Tokenization)
- 텍스트를 문장 단위로 나누는 과정
- 예: "나는 한국인이야. 너는?" → ["나는 한국인이야.", "너는?"]
- 문자 토큰화 (Character Tokenization)
- 텍스트를 개별 문자 단위로 나누는 과정
- 예: "나는" → ["나", "는"]
Stopward Removal : 불용어 제거
- 텍스트 분석에서 중요하지 않은 단어들을 제거하는 과정
Stopwords의 예
- 영어: "the", "is", "at", "which", "on" 등
- 한국어: "이", "그", "저", "것", "등", "들" 등
Stopwords 목록
- 언어마다 다른 stopwords 목록을 사용한다.
- 도메인이나 작업에 따라 사용자 정의의 불용어사전을 사용할 수 있다.
Stemming & Lemmatization : 어간추출과 표제어 추출
- 같은 의미의 단어들을 같은 형태로 변환하는 작업
Stemming(어간 추출)
- 설명: 단어에서 접사(접두사, 접미사 등)를 제거하는 과정으로, 주로 규칙 기반 알고리즘을 사용하여 수행합니다.
- 특징:
- 빠르지만 부정확할 수 있으며, 실제 단어로 변환되지 않을 수도 있습니다.
- 예시:
- "running" → "run"
- "better" → "better"
- "cats" → "cat"
- "beautiful" → "beauti" (실제 단어가 아님)
Lemmatization(표제어 추출)
- 설명: 단어를 기본 사전형 단어로 변환하는 과정으로, 주로 사전을 기반으로 수행됩니다.
- 특징:
- 어간 추출보다 더 정교하고 정확하며, 정확하지만 더 많은 리소스를 필요로 할 수 있습니다.
- 예시:
- "running" → "run"
- "better" → "good"
- "was" → "be"
- "mice" → "mouse"
Cleaning : 정제
구분/방법/예시
| 불필요한 문자 제거 | - 특수문자 및 숫자 제거<br> - HTML 태그 제거<br> - 텍스트 내 URL 제거 | "Hello, World! 123" → "Hello World"<br> "<p>Hello World</p>" → "Hello World" |
| 공백 정리 | - 불필요한 공백 제거, 여러 공백을 하나로 통일 | "Hello World!" → "Hello World" |
| 이모티콘/이모지 처리 | - 제거 또는 텍스트로 변환 | 😊 → "smile" |
| 축약어 확장 | - 일반적인 축약어를 풀어서 표현 | "don't" → "do not" |
| 대소문자 변환 | - 모든 문자를 대문자 또는 소문자로 변환 | "Hello World" → "hello world" |
| 철자 오류 수정 | - 철자 오류 수정 | |
| 중복 제거 | - 반복되는 단어나 문장 제거 |
텍스트 표현 방법
- BoW(Bag of Words)
- TF-IDF
- Word Embedding
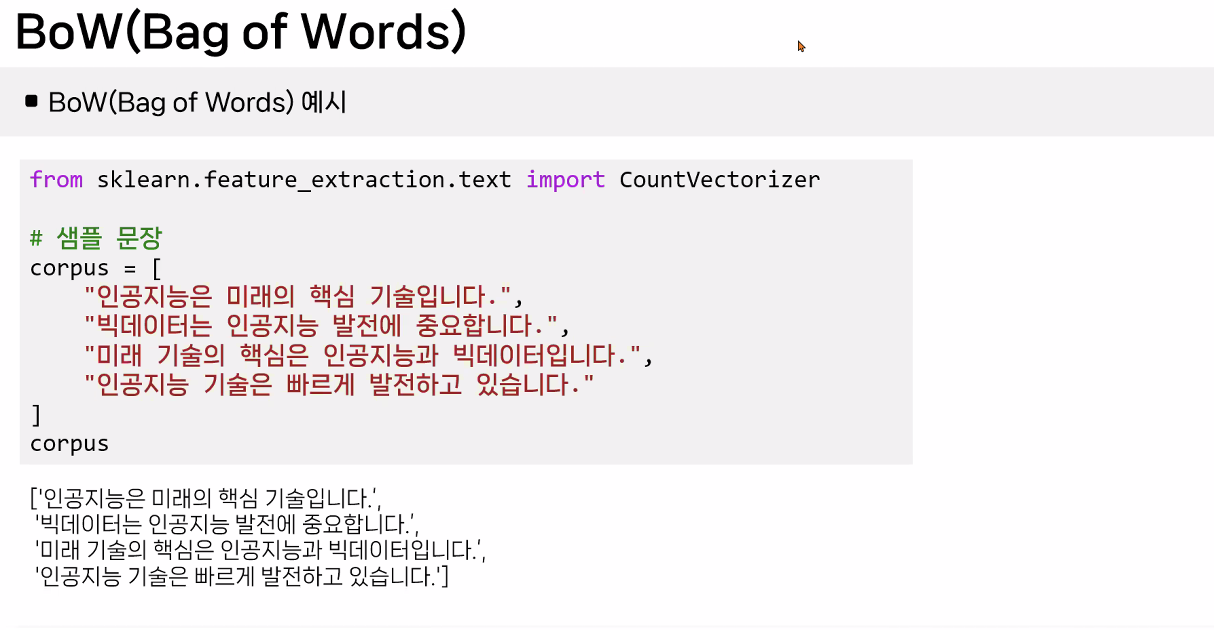
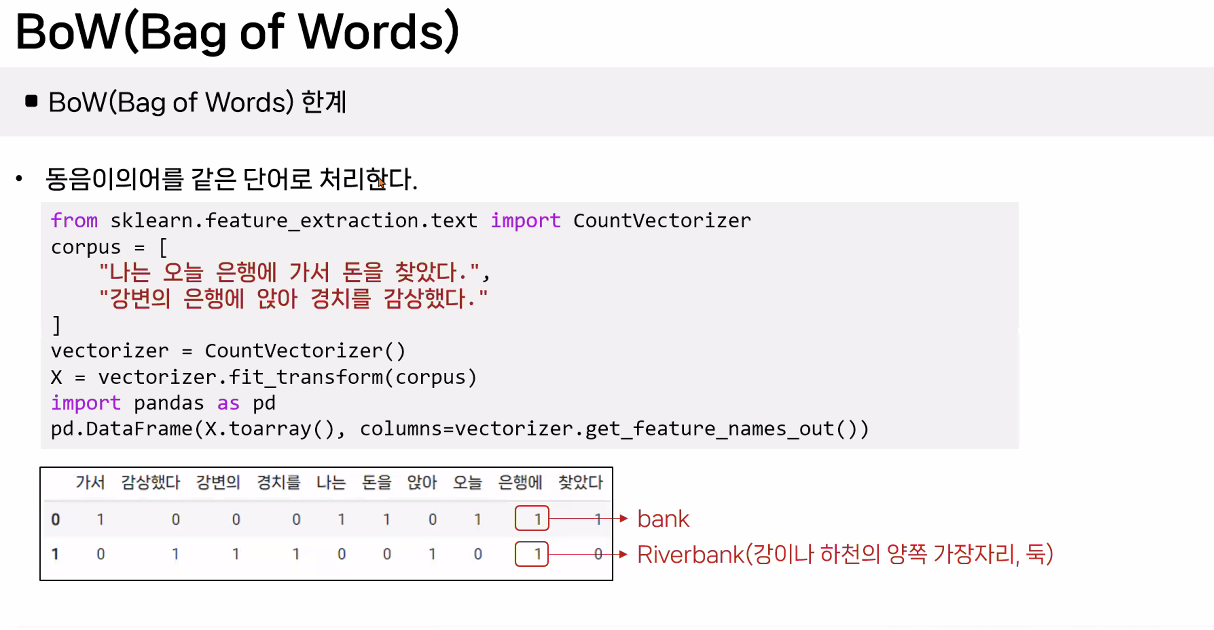
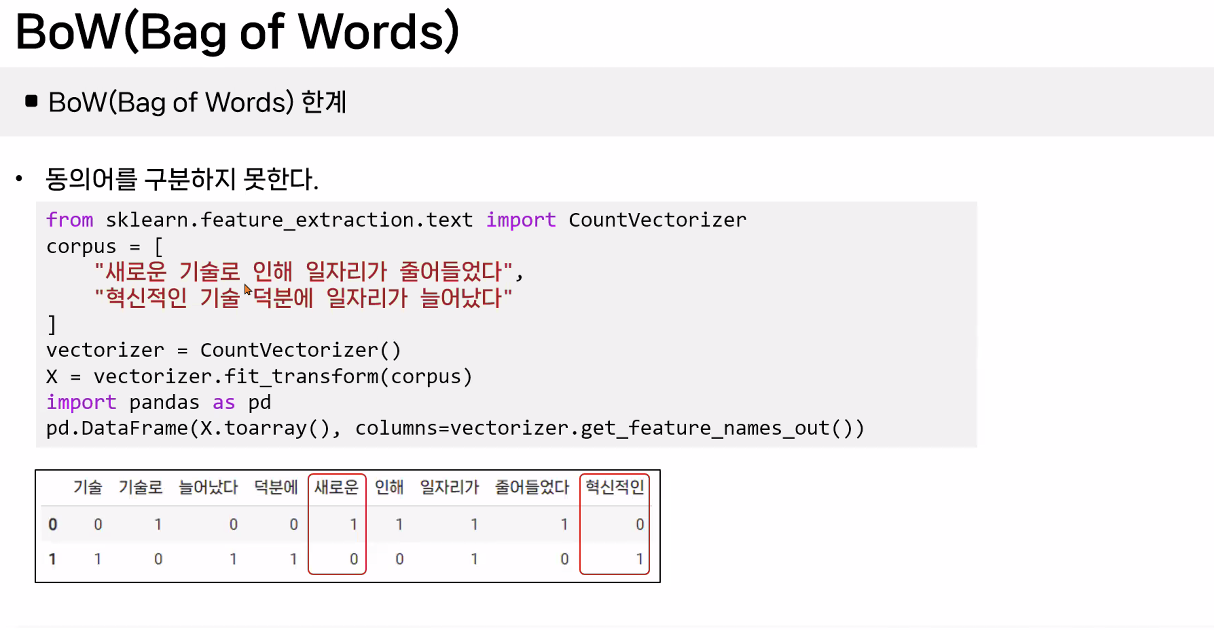
BoW(Bag of Words) 개념
- 문서에서 단어의 빈도를 세어 벡터로 표현하는 방법
주요 특징
- 단어의 발생 빈도에 초점
- 순서를 고려하지 않고 중복 발생 빈도를 중요하게 취급한다.
- 벡터화
- 문서를 고정된 크기의 벡터로 변환한다.
- 각 벡터의 길이는 분석 대상이 되는 전체 단어 집합(보카불러리)의 크기와 동일하다.
- 벡터의 각 요소는 해당 단어가 문서에 등장한 횟수를 나타낸다.
- 보카불러리(Vocabulary)
- 문서 전체에 사용된 모든 고유한 단어들의 집합.
- 이 집합의 크기가 BoW 벡터의 차원을 결정한다.
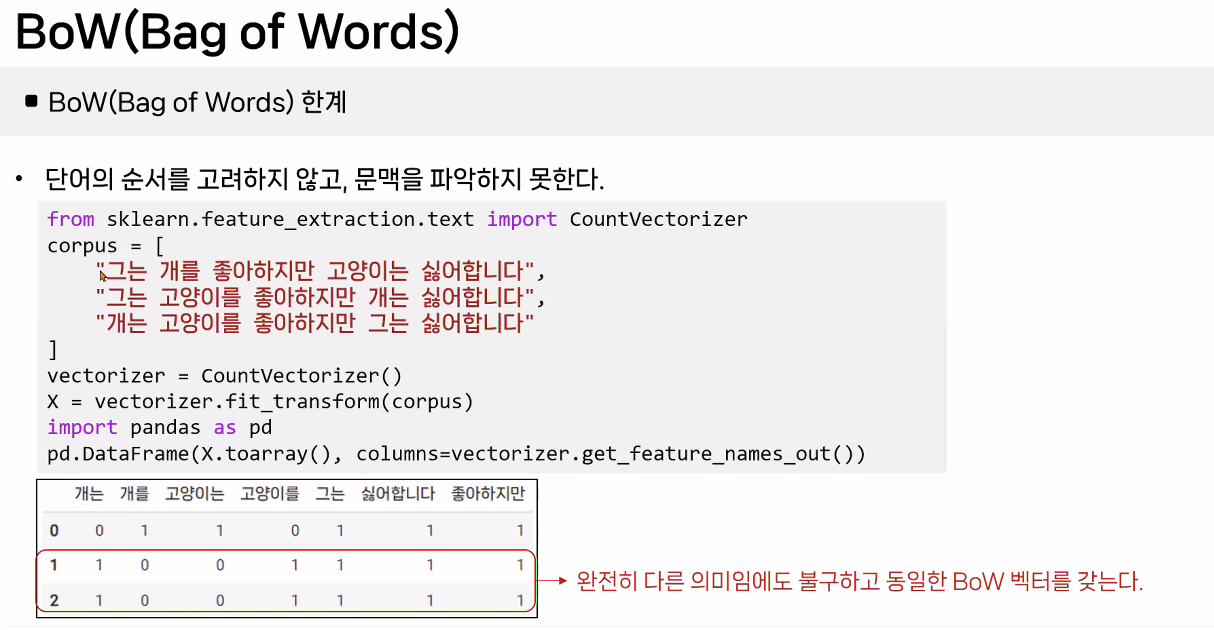
BoW(Bag of Words) 예시


TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF 개념
단어의 출현 빈도를 고려하여 가중치를 적용하는 방법으로, 문서 내에서 단어의 중요도를 평가하는 데 사용합니다.
구분의미내용
| TF | Term Frequency (단어빈도) | - 특정 문서 내에서 특정 단어의 출현 빈도<br> - 이 값이 높을수록 문서에서 중요하다고 생각할 수 있음 |
| DF | Document Frequency (문서 빈도) | - 특정 단어가 등장한 문서의 수<br> - 단어 자체가 문서군 안에서 자주 사용되고, 흔하게 등장한다는 의미 |
| IDF | Inverse Document Frequency (역문서 빈도) | - DF의 역수로 DF에 반비례하는 수<br> - 특정 단어가 전체 문서에서 얼마나 드문지 나타내는 수 |
| TF-IDF | TF와 IDF를 곱한 값 | - 대부분의 문서에 자주 등장하는 단어는 낮은 중요도로 계산<br> - 특정 문서에만 자주 등장하는 단어는 높은 중요도로 계산 |
BoW, TF-IDF 응용사례
뉴스기사 카테고리 분류
- 설명: 뉴스 기사를 스포츠, 정치, 경제 등 다양한 카테고리로 분류하는 문제를 다루는 사례입니다.
- 데이터 수집
- 내용: 뉴스기사 제목과 본문 데이터를 수집합니다.
- BoW 벡터화
- 내용: 각 기사를 BoW로 벡터화하여 단어의 빈도로 표현합니다.
- TF-IDF 변환
- 내용: BoW로 표현된 벡터를 TF-IDF로 변환하여 단어의 중요도를 반영합니다.
- 모델 학습
- 내용: 로지스틱회귀, 나이브베이즈, 서포트벡터머신(SVM) 등의 분류 모델을 학습시킵니다.
- 모델 활용
- 내용: 학습된 모델을 사용하여 새로운 뉴스기사를 적절한 카테고리로 분류합니다.'
BoW, TF-IDF 응용사례
감성 분석(Sentiment Analysis)
- 설명: 영화의 리뷰나 상품 리뷰의 감성을 긍정, 부정, 중립 등으로 분류하는 문제를 다루는 사례입니다.
- 데이터 수집
- 내용: 리뷰 텍스트와 해당 리뷰의 긍정/부정/중립 레이블을 포함한 데이터를 수집합니다.
- 텍스트 전처리
- 내용: 불용어 제거, 소문자 변환, 특수문자 제거 등의 전처리 작업을 수행합니다.
- BoW, TF-IDF 벡터화
- 내용: 리뷰 텍스트를 BoW 또는 TF-IDF로 변환하여 표현합니다.
- 모델 학습
- 내용: 나이브 베이즈, 로지스틱 회귀, 신경망 모델 등을 사용하여 학습합니다.
- 모델 활용
- 내용: 학습된 모델을 사용하여 새로운 리뷰 텍스트의 감성을 예측합니다.
제품 리뷰 분석을 통한 트렌드 파악
- 설명: 제품 리뷰 데이터를 분석하여 소비자 선호도와 시장 트렌드를 파악하는 문제를 다룹니다.
- 데이터 수집
- 내용: 온라인 쇼핑몰에서 제품 리뷰 데이터를 수집합니다.
- BoW, TF-IDF 벡터화
- 내용: 리뷰 텍스트를 BoW 또는 TF-IDF로 벡터화합니다.
- 토픽 모델링
- 내용: LDA(Latent Dirichlet Allocation)와 같은 주제 모델링 기법을 사용하여 주요 주제를 추출합니다.
- 트렌드 분석
- 내용: 특정 주제에 대한 리뷰의 시간적 변화를 분석하여 시장 트렌드를 파악합니다.
- 모델 활용
- 내용: 어떤 제품이나 기능이 인기를 끌고 있는지, 소비자들의 관심이 어디에 집중되는지를 파악합니다.
문서 유사도 평가
- 설명: 문서 간의 유사도를 평가하여, 예를 들어 추천 시스템에서 유사한 콘텐츠를 추천하는 문제를 다룹니다.
- 데이터 수집
- 내용: 문서 데이터셋(기사, 논문, 블로그 글 등)을 수집합니다.
- TF-IDF 벡터화
- 내용: 문서를 TF-IDF로 벡터화하여 각 문서의 벡터 표현을 만듭니다.
- 유사도 계산
- 내용: 코사인 유사도(cosine similarity) 등을 사용하여 문서 간의 유사도를 계산합니다.
- 결과
- 내용: 유사한 문서를 찾거나 추천 시스템에 활용합니다.
Word Embedding 개념 및 특징
- 단어를 고정된 크기의 실수 벡터로 변환하는 기법
- 단어를 고정된 크기의 실수 벡터로 변환하는 기법
- 목적
- 단어의 의미론적, 문법적 특성을 수치화
- 단어 간 관계를 벡터 연산으로 표현
- 기계학습 모델의 입력으로 사용 가능한 형태로 변환
Word Embedding 주요 특징
- 비슷한 의미의 단어는 벡터 공간에서 가까이 위치
- 비슷한 의미를 가진 단어들은 벡터 공간에서 서로 가까운 위치에 있습니다.
- 단어 간 관계를 벡터 연산으로 표현 가능
- 예를 들어, "king - man + woman ≈ queen"과 같이 벡터 연산을 통해 단어 간의 관계를 표현할 수 있습니다.
- 저차원 밀집 벡터(dense vector)로 표현
- 일반적으로 50~300차원의 저차원 벡터로 표현됩니다.
Word Embedding 최근 트렌드
- 문맥을 고려한 동적 임베딩 (BERT, ELMo 등)
- 단어의 문맥적 의미를 반영하기 위해 문맥에 따라 다르게 임베딩하는 기법.
- 다국어 임베딩
- 여러 언어를 한꺼번에 임베딩하여 다국어간의 의미 관계를 학습하는 기법.
- 도메인 특화 임베딩
- 특정 도메인에 특화된 언어 모델을 통해 해당 분야에 특화된 임베딩을 생성하는 기법.
머신러닝 알고리즘
- Naive Bayes
- 확률에 기반한 분류 알고리즘으로, 텍스트 분류에 주로 사용됩니다.
- SVM (Support Vector Machine)
- 텍스트 데이터의 분류 문제에 효과적인 알고리즘입니다.
- Logistic Regression
- 이진 분류 문제에 자주 사용됩니다.
딥러닝 알고리즘
RNN (Recurrent Neural Network)
- 순환신경망
- 시퀀스 데이터를 처리하는 데 적합한 신경망으로, LSTM(Long Short-Term Memory)과 GRU(Gated Recurrent Unit)가 많이 사용됨.
- 순차 데이터 처리에 적합.
CNN (Convolutional Neural Network)
- 컨볼루션 신경망
- 주로 이미지 처리에 사용되지만, 텍스트 분류에서도 사용될 수 있음.
- 국부적 특징 추출에 유용.
Transformer
- 최근 NLP 분야에서 가장 주목받는 모델로, BERT, GPT 등이 대표적.
- 자기주의 메커니즘을 이용한 고성능 모델.
RNN(Recurrent Neural Networks)
▪️연속적인 데이터에 동작하는 RNN
▪️RNN의 작동 원리
입력 레이어: 시퀀스의 각 요소가 RNN의 입력으로 주어진다.
• 은닉 레이어: 각 타임스텝에서 RNN은 현재 입력과 이전 상태를 결합하여 새로운 상태를 생성한다.
• 출력 레이어: 현재 시점의 예측 또는 중간 표현을 생성한다.
• 순환 연결: RNN은 각 타임스텝에서 새로운 상태와 출력을 생성하며, 이 상태는 다음 타임스텝으로 전달된다.
▪️이전 단계의 정보가 다음 단계로 전달됨
▪️RNN 유형
▪️RNN 유형
many to one : classification : Positive or Negative ?
one to many : image captioning / classification : 품사 태깅
many to many
▪️RNN의 한계와 개선된 구조
RNN의 한계와 개선된 구조
RNN의 한계
- 장기 의존성 문제(Long-term dependency):
- 긴 시퀀스에서 이전의 정보를 잊어버리는 경향이 있음.
- 기울기 소실/폭발 문제:
- 역전파 과정에서 기울기가 사라지거나 폭발할 수 있음. 이로 인해 학습이 어려워지고, 모델의 성능이 저하될 수 있음.
- 계산 비용:
- 시퀀스의 길이에 따라 계산 비용이 크게 증가할 수 있음.
- 병렬 처리의 어려움:
- 순차적 처리로 인해 GPU 활용이 제한적임.
RNN의 개선된 구조
- LSTM (Long Short-Term Memory):
- 중요한 정보를 오래 기억하고 불필요한 정보를 잊어버리는 메커니즘을 통해 RNN의 한계 극복.
- GRU (Gated Recurrent Unit):
- LSTM과 유사한 목적을 가지고 있으며, 구조가 더 단순하여 학습 속도가 빠름.
- Transformer:
- 최근에는 Transformer 아키텍처가 많은 순차 데이터 처리 작업에서 RNN을 대체하고 있음.
LSTM의 정의 및 주요 특징
- 정의: RNN의 기본 구조를 확장하여 중요한 정보를 오랫동안 기억하고, 불필요한 정보는 잊어버리는 기능이 있음.
주요 특징
- 기억셀(Memory Cell):
- LSTM의 핵심 요소로, 시퀀스 데이터의 각 단계에서 중요한 정보를 유지하거나 잊는 결정을 내림.
- 게이트(Gate):
- 세 가지 게이트로 구성되어 있으며, 각 게이트는 시그모이드 함수와 같은 비선형 활성화 함수를 사용하여 정보를 선택적으로 통과시킴.
- 입력 게이트(Input Gate): 새로운 정보를 얼마나 현재의 기억 셀에 추가할 지 결정.
- 망각 게이트(Forget Gate): 이전 기억을 얼마나 잊을지 결정.
- 출력 게이트(Output Gate): 최종적으로 출력할 정보 결정.
- 셀 상태(Cell State):
- 이전 단계에서 전달된 중요한 정보를 전달하며, 각 단계에서 게이트의 제어를 받아 업데이트 됨.
LSTM(Long Short-Term Memory)의 동작 원리
- 입력 게이트: 새로운 정보를 받아들일지 여부를 결정한다.
- 망각 게이트: 현재 셀 상태에서 불필요한 정보를 제거한다.
- 셀 상태 업데이트: 새로운 정보를 추가하여 업데이트 한다.
- 출력 게이트: 셀 상태를 기반으로 최종 출력을 생성한다.
GRU(Gated Recurrent Unit)
GRU의 정의 및 특징
- 정의:
- GRU는 LSTM과 유사한 목적을 가지고 있는 순환 신경망의 한 종류로, LSTM의 구조를 단순화하여 계산 효율성을 높이면서도 장기 의존성을 처리하는 능력을 유지합니다.
- 특징:
- 구조: GRU는 LSTM보다 구조가 간단하고 학습 속도가 빠르며, 비슷한 성능을 제공하는 경우가 많습니다.
- 게이트 구조:
- 업데이트 게이트(Update Gate): 입력 정보와 이전 상태를 결합하여 새로운 정보를 얼마나 반영할지 결정합니다.
- 리셋 게이트(Reset Gate): 이전 상태를 얼마나 잊을지 결정하며, 현재 입력과 결합하여 새로운 상태를 생성합니다.
- 은닉 상태(Hidden State): 단일 은닉 상태를 유지하며, 이는 LSTM의 셀 상태와 은닉 상태를 통합한 형태입니다.
Transformer 모델
Transformer 모델의 기본 개념
- 개발 배경:
- 2017년 Google의 "Attention Is All You Need" 논문에서 소개된 혁신적인 딥러닝 아키텍처이다.
- 주로 자연어 처리(NLP) 분야에서 사용되는 딥러닝 모델로, 최근 LLM(대형 언어 모델) 모델의 기반이 되고 있다.
- 특징:
- 구조: 순환 신경망(RNN)이나 LSTM과 달리 순환구조를 사용하지 않고, attention 메커니즘을 활용한다.
- self attention 메커니즘: 언어가 가진 문법적 구조와 각 문장 간의 관계성을 이해하는 데 도움을 준다.
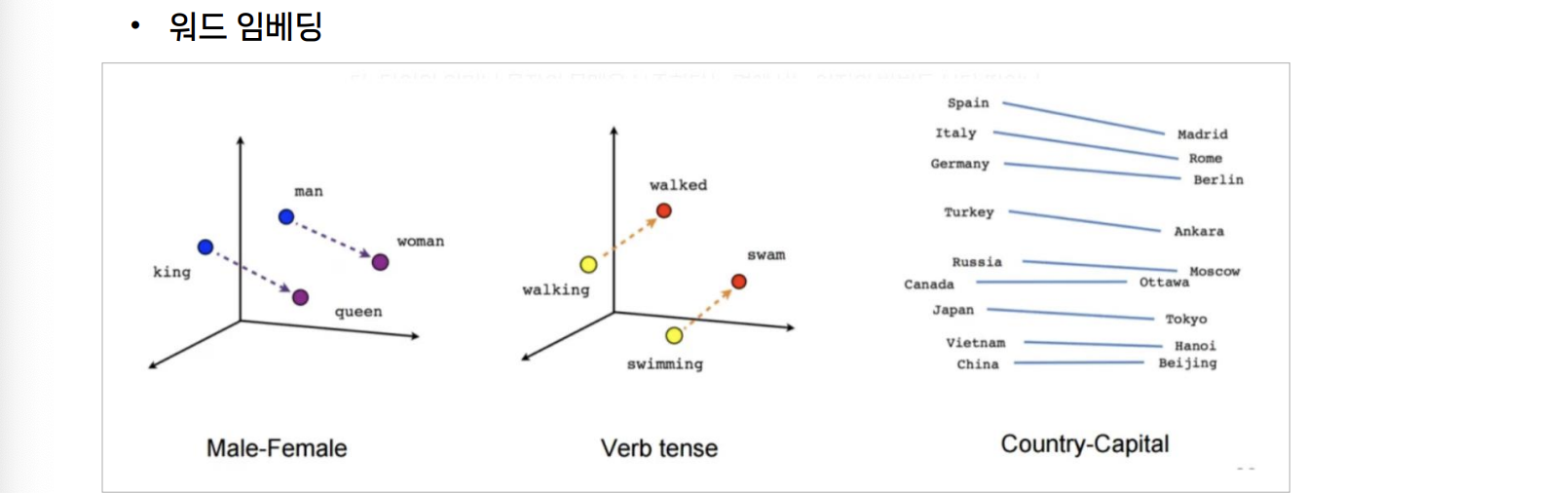
- 워드 임베딩: 단어들을 벡터 공간에 위치시켜 의미적 유사성을 반영한다.
- 비슷한 언어는 비슷한 숫자로 매핑된다.
- 구성 요소: 언어를 이해하는 인코더와 언어를 생성하는 디코더로 구성되어 있으며, 디코더를 중심으로 빠르게 발전하고 있다.
Word2Vec 으로 단어 임베딩하기 (Word2Vec word embeddings)
기존의 빈도 기반 임베딩 방법들은 단어 벡터 간 관계가 없거나 (one-hot encoding) 제한적이었다 (SVD). Word2Vec은 분산된 표상 (distributed representation) 이라는 아이디어에 기반해서, 벡터의…
medium.com
Transformer 모델의 활용 분야
활용 분야
- 번역 (Translation): 문장 번역에서 높은 정확도를 자랑한다.
- 텍스트 요약 (Summarization): 문서나 기사에서 중요한 정보를 요약한다.
- 문장 생성 (Text Generation): 잘못 답변, 채팅봇, 스토리 생성 등 다양한 응용에서 사용된다.
- 비고: Transformers는 BERT, GPT, T5 등 현대 NLP의 핵심 모델의 기반이 되었으며, 컴퓨터비전 등 다른 분야로도 확장되고 있다.
LLM(Large Language Model)의 정의 및 주요 특징
- 거대한 양의 텍스트 데이터로 학습된 인공지능 모델: LLM은 대규모 텍스트 데이터를 학습하여 언어를 이해하고 생성하는 모델이다.
- 대규모 데이터 학습: 수십억에서 수천억 개의 매개변수를 가진다. 이는 모델이 복잡한 언어 구조를 이해하고 처리하는 데 도움을 준다.
- 학습 데이터: 인터넷에서 수집된 방대한 양의 데이터를 기반으로 학습한다. 이러한 데이터는 다양한 언어와 주제를 포함한다.
- 학습 아키텍처: 주로 Transformer 구조를 기반으로 한다. Transformer는 병렬 처리가 가능하여 효율적인 학습이 가능하다.
- 문맥 이해 능력: LLM은 문맥과 의미를 이해하는 데 뛰어난 능력을 발휘한다. 이는 자연어 처리 작업에서 정확한 의미를 파악하고 관련 정보를 추론하는 데 도움을 준다.
사전학습과 미세 조정
- 사전학습(Pre-training)과 미세 조정(Fine-tuning):
- 사전학습: 모델은 먼저 방대한 양의 텍스트 데이터를 사용하여 일반적인 언어 패턴을 학습한다. 이 단계에서 학습된 모델은 다양한 언어 이해 능력을 갖추게 된다.
- 미세 조정: 특정 작업(예: 번역, 요약, 질의응답 등)에 맞게 사전학습된 모델을 소규모 데이터로 추가 학습한다. 이를 통해 특정한 응용에 필요한 능력을 강화한다.
LLM의 응용 분야
• 주요 기능
✓ 텍스트 생성(문법에 맞게, 창의적으로), 질문답변, 번역, 요약, 코드생성 및 이해, 감성분석 등
• 응용분야
✓ 챗봇, 자동화된 고객 서비스, 콘텐츠 생성 등
▪️대표적인 LLM
• GPT (Generative Pre-trained Transformer) 시리즈
• BERT (Bidirectional Encoder Representations from Transformers)
• T5 (Text-to-Text Transfer Transformer)
• LaMDA (Language Model for Dialogue Applications)
▪️해결해야 할 문제
• 허위정보 생성
• 윤리적 문제 : 편향, 혐오발언 노출 위험
• 리소스 관리 : 모델의 크기와 복잡성으로 이해 학습과 추론에 높은 컴퓨팅 자원을 요구
CHT GPT의 이해
GPT
다음 단어를 예측하는 언어모델
확률과 통계 기반

ChatGPT
Pre-training
- Generative Pretrained Transformer:
- Generative: 다음 단어를 예측하는 방식으로 학습한다.
- Pre-trained: 많은 양의 데이터를 사전에 훈련한다.
- Transformer: 신경망에 기반한 인코더-디코더 구조를 사용한다.
Alignment
- chatGPT:
- 대화할 수 있게 GPT를 fine-tuning 한 것이다.
이후에는 Prompt - 대답의 쌍으로 학습하는 단계를 거친다.
ChatGPT의 학습 단계
alignment
SFT (Supervised Fine-Tuning)
- 프롬프트 목록을 만든다.
- 라벨러들이 예상 답변을 작성한다.
- 지도학습을 진행한다.
RM (Reward Model)
- SFT 모델이 프롬프트에 대해 여러 개의 문장을 생성한다.
- 라벨러들이 문장의 순위를 매겨 라벨링한다.
- 라벨링한 결과를 학습한다.
PPO (Proximal Policy Optimization)
- 프롬프트와 응답이 주어지면 RM 모델이 보상을 제공하며 강화학습을 진행한다.
=> chat gpt가 이토록 잘 작동하는 것에 대하여 수학적으로 밝혀진 사실이 없음. 어찌어찌 시작했더니 잘 되더라.
=> 이미지, 텍스트를 활용하여 딥러닝 모델을 새로 만들기에는 방대한 자원이 필요함. 따라서 기존에 전이 학습되어진 모델을 활용하여 개인의 목적에 맞게 fine tuning을 진행하는 것이 바람직.
=> 무엇을 좋아하는지 찾기 -> 그것을 하기 위하여 어떤 기술이 필요한지 알기
*문제정의, 기획에 대한 노력이 모델링 보다 더 중요한 작업임.